Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Empowering IT & AI Insights with Losers
Empowering IT & AI Insights with Losers


Chào các bạn, mình là loser1 đến từ Learning AI With Losers. Hôm nay, mình sẽ chia sẻ về FlashMLA – một kernel decoding hiệu quả cho Multi-Head Latent Attention (MLA) trên GPU Hopper, được tối ưu cho các chuỗi dữ liệu có độ dài biến đổi. Bài viết này mình sẽ đi từng bước, giải thích chi tiết về nền tảng, cách thức hoạt động, hiệu năng cũng như các ứng dụng thực tiễn của FlashMLA. Cùng theo dõi nhé! 😎
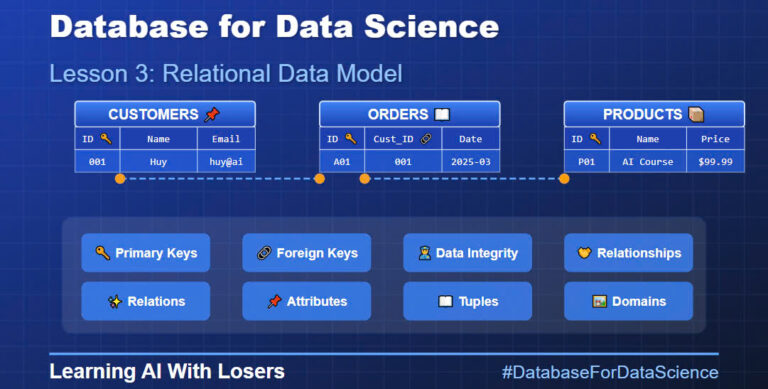
Kiến trúc Transformer:
Transformer là nền tảng cho các mô hình ngôn ngữ hiện đại. Nó sử dụng cơ chế attention để xử lý dữ liệu đầu vào, giúp các mô hình có khả năng “tập trung” vào những thông tin quan trọng.
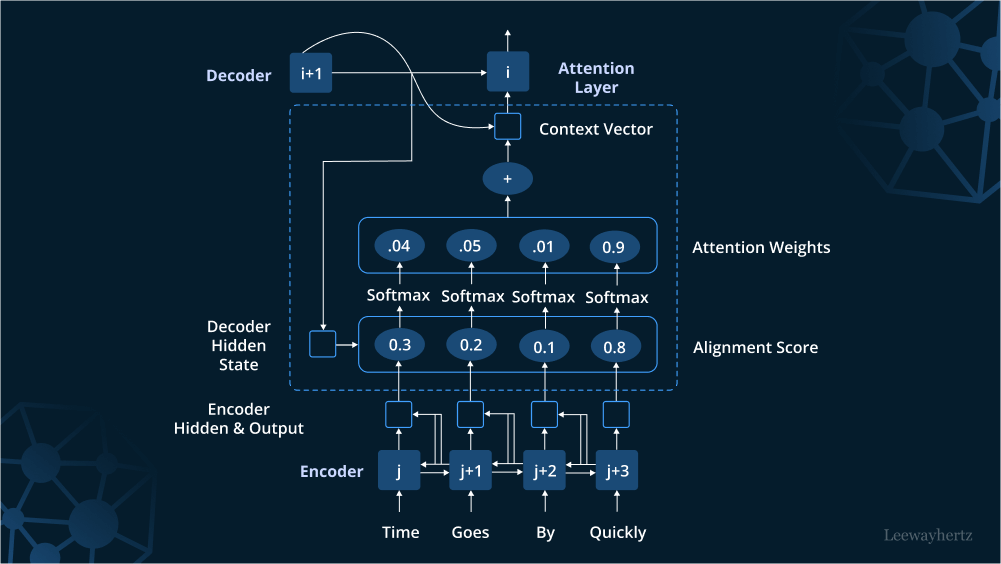
Attention mechanism là một kỹ thuật then chốt trong các mô hình ngôn ngữ lớn, cho phép mô hình tập trung vào các phần quan trọng của dữ liệu đầu vào. Nó hoạt động như sau:
Attention(Q, K, V) = softmax(QK^T/√d_k)VTrong đó:
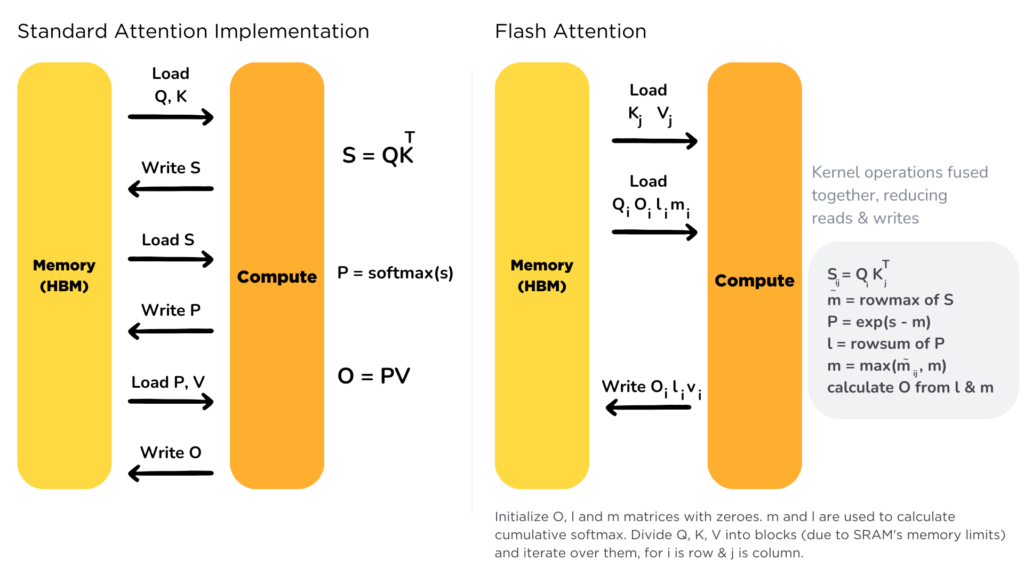
Flash Attention giải quyết các vấn đề trên bằng cách:
# Pseudo code của Flash Attention
for Bi in range(n_blocks):
mi = max(Qi @ Ki.T) # Block maximum
li = sum(exp(Qi @ Ki.T - mi)) # Block sum
Oi = exp(Qi @ Ki.T - mi) @ Vi # Block output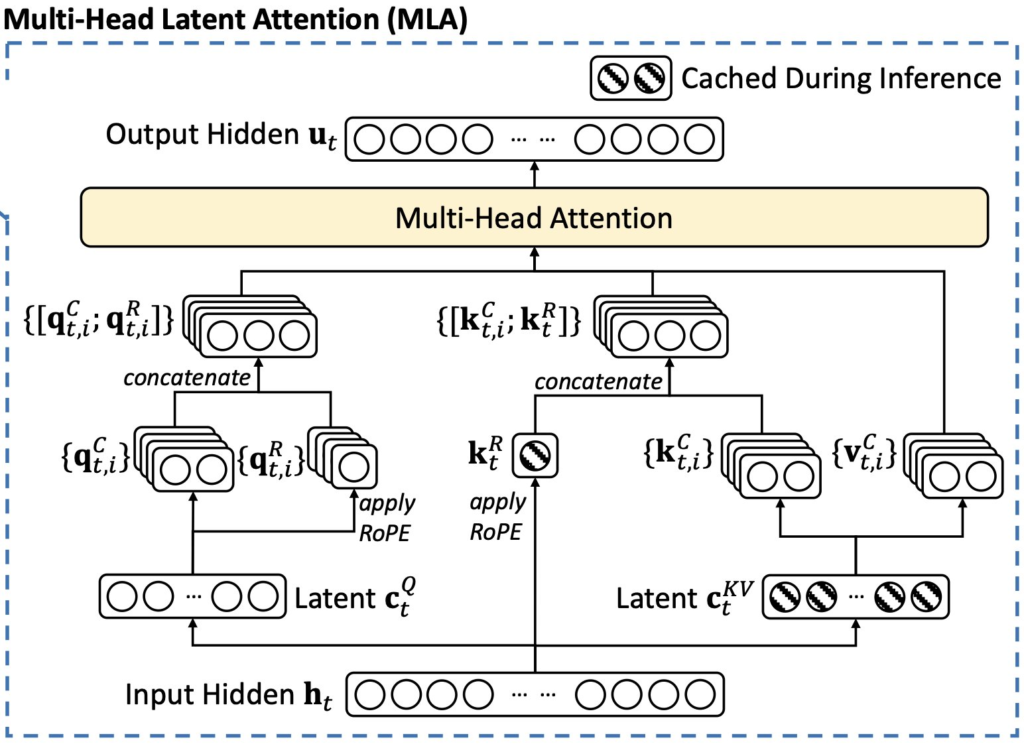
MLA là phiên bản cải tiến của Multi-Head Attention:
# Pseudo code của MLA
L = f(K) # Latent representation
A = g(Q, L) # Attention scores
O = A @ V # Output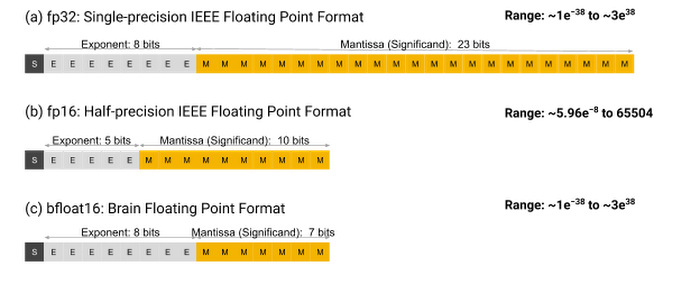
BF16 (Brain Floating Point 16-bit) là một định dạng số thực 16-bit được thiết kế để cân bằng giữa hiệu năng tính toán và độ chính xác.
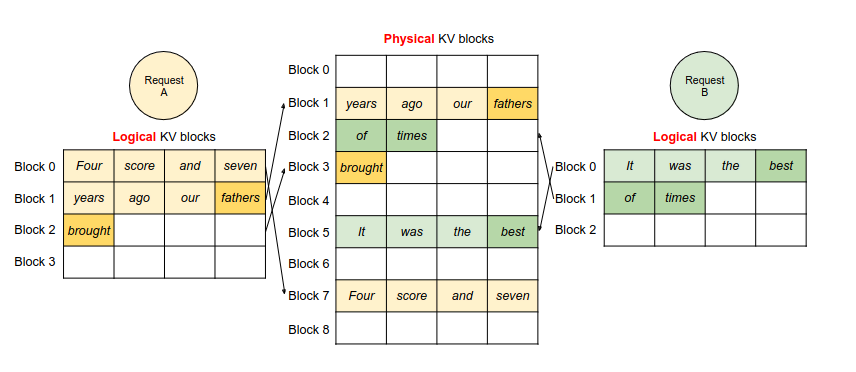
Paged KV Cache là một chiến lược quản lý bộ nhớ tối ưu, được thiết kế để xử lý KV cache (Key-Value cache) một cách hiệu quả trên GPU:
FlashMLA được hiện thực dưới dạng các CUDA kernel chuyên dụng, tận dụng tối đa kiến trúc của GPU Hopper:
FlashMLA kết hợp ưu điểm của:
Bây giờ khi đã hiểu những khái niệm cơ bản này, chúng ta sẽ dễ dàng nắm bắt được cách FlashMLA hoạt động và tại sao nó lại mang tính đột phá như vậy! 🚀
FlashMLA là một công cụ phần mềm chuyên biệt (kernel) được phát triển để tăng tốc quá trình decoding trong các mô hình ngôn ngữ lớn (LLM). Nó được thiết kế đặc biệt cho phần Multi-Head Latent Attention (MLA) – một biến thể của attention giúp nén lại bộ nhớ KV cache bằng cách sử dụng các ma trận hạng thấp. Nhờ đó, FlashMLA có thể xử lý các chuỗi có độ dài biến đổi, thường gặp trong các ứng dụng như tạo văn bản tự động, dịch máy,… Điều này giúp giảm đáng kể gánh nặng về bộ nhớ và thời gian tính toán trên các GPU hiện đại như H800 của Nvidia. 😮
1. FlashMLA Repository
Xem thêm chi tiết tại: https://github.com/deepseek-ai/FlashMLA
FlashMLA hoạt động theo những bước cơ bản sau:
Với những cải tiến trên, FlashMLA không chỉ tăng tốc quá trình decoding mà còn tối ưu hóa việc sử dụng bộ nhớ, làm cho việc triển khai các mô hình ngôn ngữ lớn trở nên hiệu quả hơn rất nhiều. 😍
Trên GPU H800 với CUDA 12.6, FlashMLA cho thấy những con số ấn tượng:
Những con số này thật sự đáng ngạc nhiên, bởi FlashMLA vừa có thể tối ưu cả về truy xuất bộ nhớ lẫn khả năng tính toán, giúp ứng dụng linh hoạt cho các tác vụ khác nhau trong quá trình inference và training của các mô hình LLM. 🚀
Trong những năm gần đây, các mô hình ngôn ngữ lớn (LLM) đã trở thành công cụ then chốt cho nhiều ứng dụng xử lý ngôn ngữ tự nhiên, từ tạo văn bản đến dịch thuật. Tuy nhiên, một trong những thách thức lớn là cơ chế attention truyền thống có độ phức tạp tính toán và sử dụng bộ nhớ theo cấp số nhân (quadratic). Điều này đặc biệt trở nên nghiêm trọng trên GPU, nơi mà băng thông bộ nhớ và khả năng xử lý song song là những yếu tố quyết định.
FlashMLA ra đời nhằm khắc phục các hạn chế này thông qua việc tối ưu hóa quá trình decoding của Multi-Head Latent Attention (MLA). MLA đã được giới thiệu trong các mô hình như DeepSeek-V2 (DeepSeek-V2 Paper)và V3, sử dụng các ma trận hạng thấp để nén lại bộ nhớ KV, từ đó tăng tốc quá trình suy luận mà không làm giảm hiệu năng của mô hình.
Trên GitHub (FlashMLA Repository), bạn có thể tìm thấy các hàm như get_mla_metadata và flash_mla_with_kvcache. Những hàm này đảm nhiệm việc tính toán metadata và xử lý attention, được xây dựng dựa trên các kernel CUDA chuyên dụng, tận dụng tối đa tensor cores và hệ thống quản lý bộ nhớ của Hopper GPUs.
| Chỉ Số | Giá Trị |
|---|---|
| Memory-Bound Performance | 3000 GB/s |
| Compute-Bound Performance | 580 TFLOPS |
Những con số này cho thấy sự tối ưu vượt trội của FlashMLA đối với cả các tác vụ phụ thuộc vào bộ nhớ và tính toán, góp phần nâng cao hiệu quả của các mô hình LLM trong các ứng dụng thực tế. 😲
So với các giải pháp như Flash Attention truyền thống, FlashMLA được thiết kế đặc biệt cho MLA – giúp nén KV cache xuống chỉ còn khoảng 5–13% so với multi-head attention (MHA) truyền thống như trong các mô hình của DeepSeek. Việc sử dụng paged KV cache với block size 64 còn giúp tối ưu hóa việc truy xuất bộ nhớ, giảm thiểu chi phí tính toán và tăng cường hiệu suất cho các tác vụ inference và training của LLM. 👍
Đối với các nhà nghiên cứu và thực hành, FlashMLA có thể được cài đặt và sử dụng khá đơn giản:
git clone https://github.com/deepseek-ai/FlashMLA.git cd FlashMLA python setup.py installpython tests/test_flash_mla.pyget_mla_metadata và flash_mla_with_kvcache để tính toán metadata và thực hiện attention: tile_scheduler_metadata, num_splits = get_mla_metadata(cache_seqlens, s_q * h_q // h_kv, h_kv) o_i, lse_i = flash_mla_with_kvcache(q_i, kvcache_i, block_table, cache_seqlens, dv, tile_scheduler_metadata, num_splits, causal=True)FlashMLA có tiềm năng được mở rộng và cải tiến theo nhiều hướng, ví dụ:
Những hướng phát triển này mở ra nhiều khả năng ứng dụng mới và là bước tiến quan trọng trong việc tối ưu hóa mô hình ngôn ngữ lớn. 🤖
Để tham khảo thêm về FlashMLA và các công nghệ liên quan, bạn có thể truy cập các repository sau:
Trích dẫn :
@misc{flashmla2025,
title={FlashMLA: Efficient MLA decoding kernel},
author={Jiashi Li},
year={2025},
publisher={GitHub},
howpublished={\url{https://github.com/deepseek-ai/FlashMLA}},
}
FlashMLA đánh dấu một bước tiến vượt bậc trong tối ưu hóa quá trình decoding của các mô hình ngôn ngữ lớn. Với khả năng xử lý các chuỗi dữ liệu có độ dài biến đổi, hỗ trợ BF16, và áp dụng bộ nhớ cache kiểu paged với block size 64, FlashMLA không chỉ đạt hiệu năng ấn tượng về cả băng thông bộ nhớ lẫn tính toán mà còn mở ra những khả năng mới cho các ứng dụng AI hiện đại trên GPU Hopper. Đây thực sự là một công cụ mạnh mẽ cho cả nghiên cứu và ứng dụng thực tế.
Hy vọng bài blog này đã giúp các bạn có cái nhìn tổng quan và chi tiết về FlashMLA. Cảm ơn các bạn đã theo dõi, và đừng quên theo dõi Learning AI With Losers để cập nhật thêm nhiều kiến thức bổ ích nhé! 😊
Chúc các bạn thành công và hẹn gặp lại trong những bài viết tiếp theo! 🎉
TechnicalAI #DeepLearning #GPUOptimization #AIResearch #LearningAIWithLosers