Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Empowering IT & AI Insights with Losers
Empowering IT & AI Insights with Losers

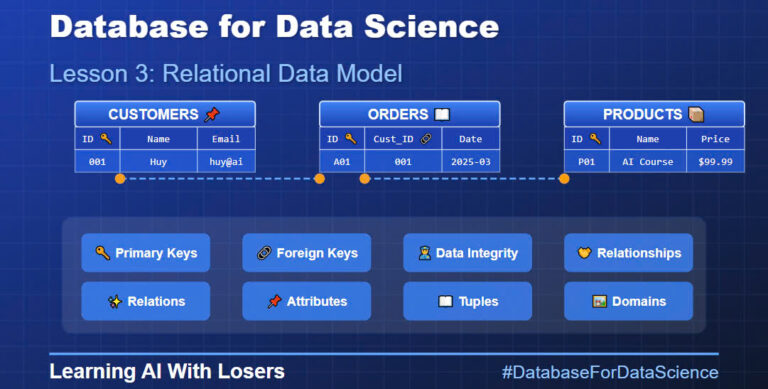
Chào mừng các bạn quay trở lại với series “Database for Data Science”! Đây là Day 2 cùng Loser1 from Learning AI with Loser! Hôm nay chúng ta sẽ cùng nhau khám phá một concept cực kỳ quan trọng mà bất kỳ ai làm việc với dữ liệu đều phải nắm vững – Entity-Relationship Model (Mô Hình Thực Thể – Kết Hợp).


Trong data science, chất lượng và cấu trúc dữ liệu ảnh hưởng trực tiếp đến hiệu quả của các mô hình phân tích và máy học. Trước khi bắt đầu viết code hay truy vấn dữ liệu, việc hiểu rõ “bản đồ” dữ liệu của bạn là bước đầu tiên không thể thiếu. ER Model:
Tạo cầu nối giữa domain experts và data scientists: Một ER diagram tốt giúp các bên liên quan dễ dàng “giao tiếp” và thống nhất về cấu trúc dữ liệu, từ đó tối ưu quá trình khai thác và sử dụng dữ liệu.
Giúp làm rõ mối quan hệ giữa các dữ liệu thực tế: Từ đó xây dựng được pipeline dữ liệu chặt chẽ từ khâu thu thập, làm sạch đến phân tích.
Tăng cường tính toàn vẹn và hiệu quả của dữ liệu: Đảm bảo rằng dữ liệu được tổ chức hợp lý, giảm thiểu lỗi và trùng lặp, giúp quá trình feature engineering và modeling trở nên thuận lợi hơn.
“Một ER Diagram tốt còn đáng giá hơn cả ngàn dòng code!” – Loser1 (tức là tôi 😅)

Thiết kế cơ sở dữ liệu (Database Design) là một bước quan trọng trong việc xây dựng hệ thống lưu trữ và quản lý dữ liệu hiệu quả. Một hệ thống CSDL được thiết kế tốt sẽ:
✅ Tối ưu hóa hiệu suất truy vấn và xử lý dữ liệu.
✅ Đảm bảo tính toàn vẹn (Integrity) và nhất quán của dữ liệu.
✅ Hỗ trợ mở rộng (Scalability) khi dữ liệu tăng trưởng.
✅ Giảm dư thừa dữ liệu (Redundancy) và tối ưu hóa lưu trữ.
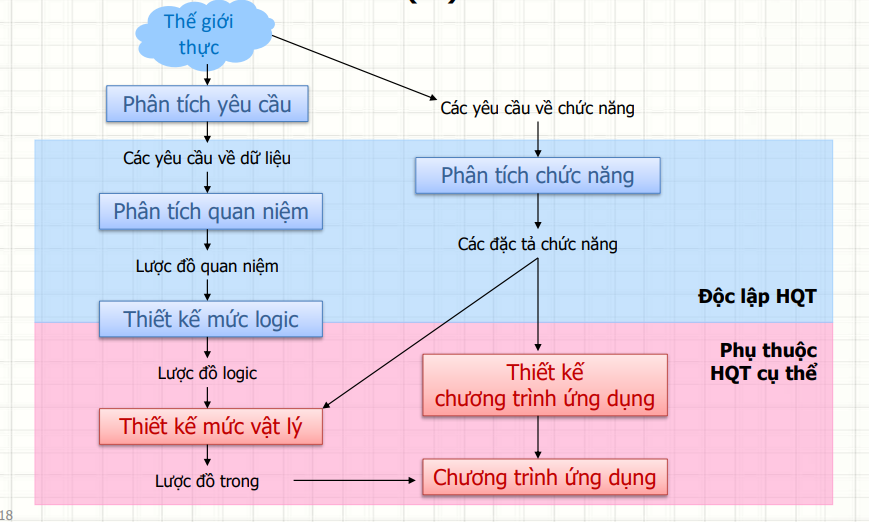
Quy trình thiết kế CSDL bao gồm hai giai đoạn chính:
🔹 Giai đoạn DBMS độc lập (DBMS Independent): Không phụ thuộc vào hệ quản trị CSDL cụ thể.
🔹 Giai đoạn DBMS cụ thể (DBMS Specific): Áp dụng vào một hệ quản trị CSDL cụ thể như MySQL, PostgreSQL, SQL Server, v.v.
Đây là giai đoạn thiết kế ở mức trừu tượng, chưa quan tâm đến việc sử dụng hệ quản trị CSDL nào. Mục tiêu của giai đoạn này là xây dựng một mô hình dữ liệu logic phản ánh đúng yêu cầu thực tế.
🔹 Mô tả nhu cầu thực tế của hệ thống từ người dùng và doanh nghiệp.
🔹 Xác định yêu cầu dữ liệu: Những thông tin nào cần lưu trữ, mối quan hệ giữa các thực thể.
Ví dụ: Khi xây dựng hệ thống quản lý dữ liệu khách hàng cho một công ty thương mại điện tử, chúng ta cần lưu trữ thông tin về khách hàng, đơn hàng, sản phẩm, phương thức thanh toán…
🔹 Dựa trên yêu cầu dữ liệu, xây dựng mô hình khái niệm (Conceptual Schema).
🔹 Thường sử dụng Mô hình thực thể – quan hệ (Entity-Relationship Model – ERD) để mô tả:
📝 Kết quả: Một sơ đồ ERD thể hiện dữ liệu và mối quan hệ của nó.
🔹 Chuyển mô hình ERD thành Mô hình quan hệ (Relational Model).
🔹 Định nghĩa các bảng (tables), khóa chính (primary key), khóa ngoại (foreign key).
🔹 Áp dụng Chuẩn hóa dữ liệu (Normalization) để giảm dư thừa và tăng tính toàn vẹn.
Ví dụ:
📝 Kết quả: Một lược đồ quan hệ thể hiện dữ liệu trong dạng bảng.
🔹 Xác định các chức năng của hệ thống dựa trên dữ liệu đã thiết kế.
🔹 Viết tài liệu Function Specification, mô tả chi tiết các nghiệp vụ cần thực hiện như:
Sau khi thiết kế logic, chúng ta cần chuyển đổi mô hình này thành hệ thống thực tế bằng cách chọn một hệ quản trị cơ sở dữ liệu cụ thể.
🔹 Tối ưu hóa lưu trữ dữ liệu trên hệ quản trị CSDL cụ thể như MySQL, PostgreSQL.
🔹 Xác định các chỉ mục (Indexes), phân vùng (Partitioning), caching, v.v.
🔹 Cấu trúc lưu trữ:
📝 Kết quả: Mô hình vật lý thể hiện dữ liệu thực tế trong DBMS.
🔹 Xây dựng phần mềm sử dụng cơ sở dữ liệu đã thiết kế.
🔹 Định nghĩa API kết nối ứng dụng với CSDL.
🔹 Xác định cách thức nhập, xuất dữ liệu trong ứng dụng.
Ví dụ:
🔹 Viết truy vấn SQL để tạo bảng, thêm dữ liệu, tối ưu truy vấn.
🔹 Cấu hình hệ thống, phân quyền truy cập dữ liệu.
🔹 Kiểm tra hiệu năng, bảo mật trước khi đưa vào hoạt động thực tế.
📝 Kết quả: Một hệ thống hoàn chỉnh kết nối CSDL với ứng dụng thực tế.
| Giai đoạn | Mô tả | Kết quả |
|---|---|---|
| Requirements Analysis | Xác định yêu cầu dữ liệu | Danh sách dữ liệu cần lưu trữ |
| Conceptual Design | Xây dựng mô hình ERD | Mô hình khái niệm |
| Logical Design | Chuyển ERD thành mô hình quan hệ | Lược đồ quan hệ (Relational Model) |
| Functional Analysis | Xác định chức năng hệ thống | Function Specification |
| Physical Design | Thiết kế cấu trúc lưu trữ dữ liệu | Mô hình vật lý |
| Application Design | Thiết kế phần mềm kết nối CSDL | Kiến trúc ứng dụng |
| Application Implementation | Viết truy vấn, triển khai ứng dụng | Hệ thống hoàn chỉnh |
Và quá trình thiết kế database phải đi từ DBMS-independent (độc lập với hệ quản trị) đến DBMS-specific (phụ thuộc vào hệ quản trị cụ thể). Nắm vững nguyên tắc này sẽ giúp bạn không bị “vendor lock-in” – tức là không bị phụ thuộc quá nhiều vào một công cụ DBMS cụ thể và cho phép linh hoạt trong việc triển khai các giải pháp data science.
Entity-Relationship Model được đưa ra bởi Dr. Peter Pin-Shan Chen vào năm 1976, và đến giờ nó vẫn là một công cụ siêu mạnh mẽ để mô tả dữ liệu.
Nguyên tắc cơ bản là gì? Đơn giản thôi:
Đây chính là cách bạn mô hình hóa thế giới thực! Nghĩ xem, mọi thứ trong thế giới này đều có thể là entities (thực thể) và có mối quan hệ (relationships) với nhau.
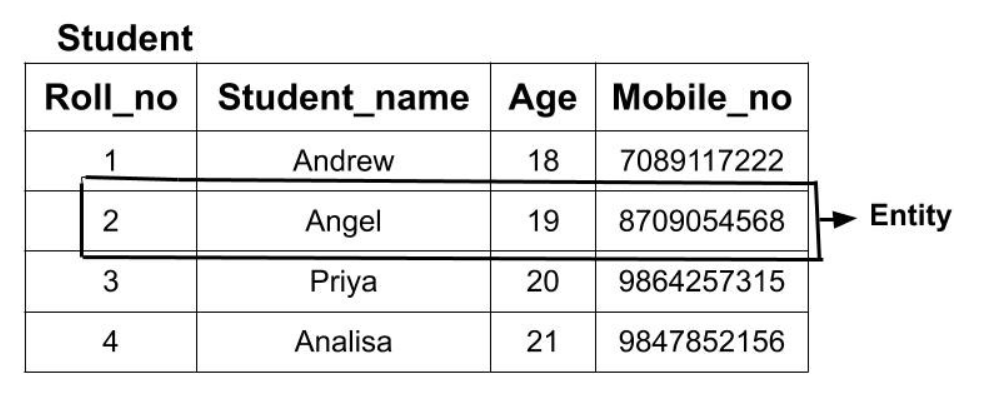

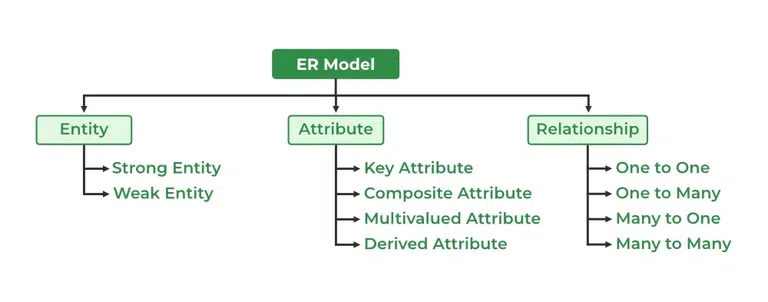
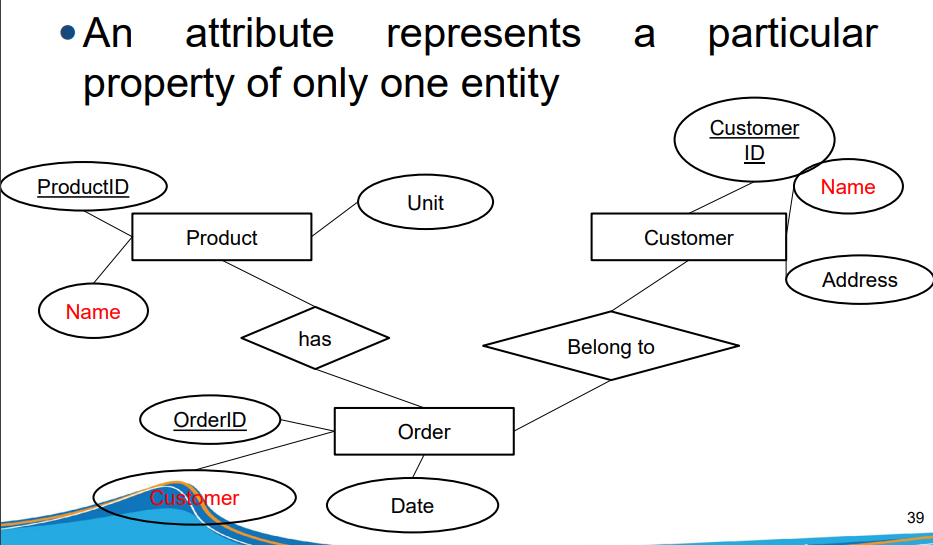
Entity (thực thể) là gì? Đơn giản thôi, đó là các đối tượng trong thế giới thực!
Trong data science, việc xác định các thực thể này giúp định nghĩa các feature (đặc trưng) cần phân tích và xây dựng mô hình.
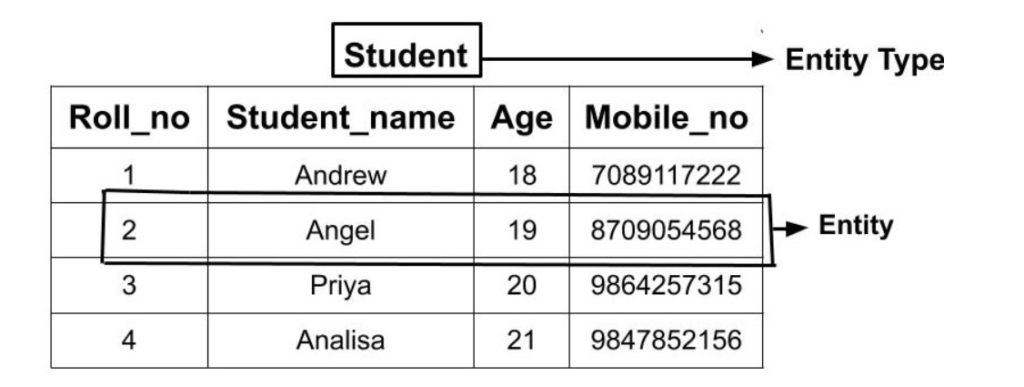
Và Entity Set (tập thực thể) là tập hợp các entities có cùng cấu trúc thông tin.Điều này rất quan trọng khi chuẩn bị dữ liệu cho việc phân tích phân khúc, dự báo hành vi,…
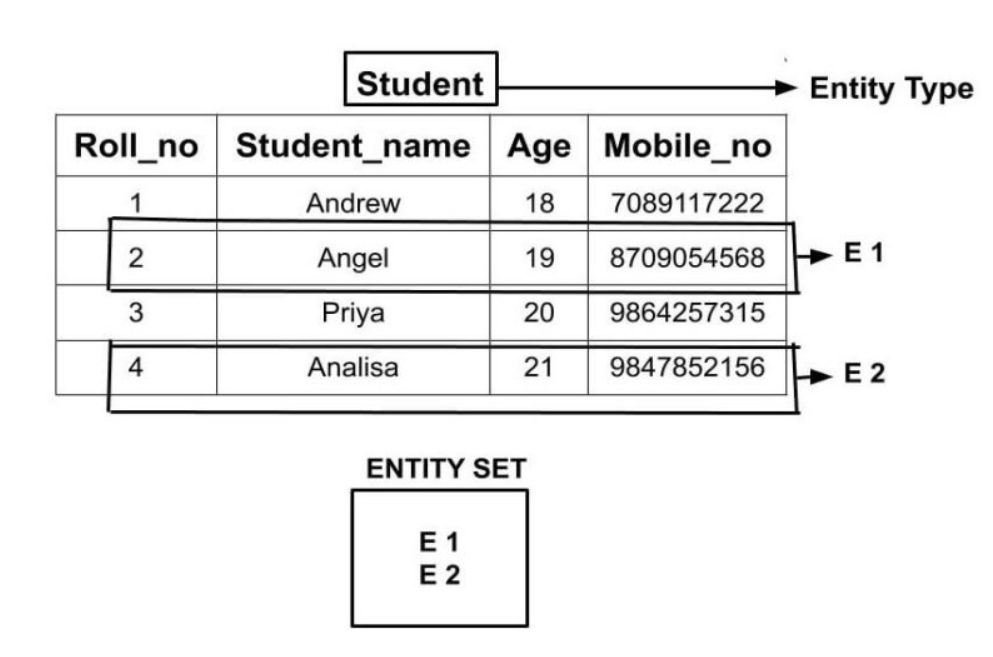
Ví dụ: Hai người “NVA” và “NVB” có tên khác nhau, mã số sinh viên khác nhau, nhưng có cùng một cấu trúc thông tin. Họ tạo thành một entity set với tên “Student”.

Mỗi entity đều có các đặc điểm riêng, gọi là attributes (thuộc tính). Và chúng có nhiều loại cực kỳ thú vị:

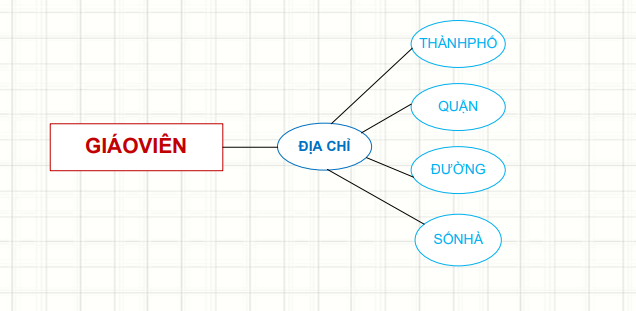
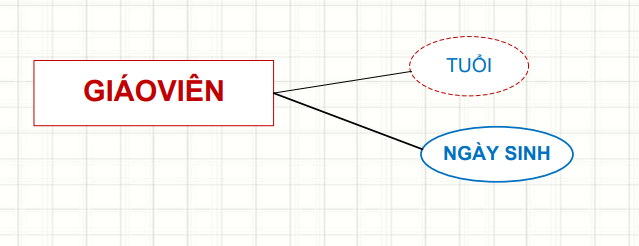
Hiểu rõ các loại thuộc tính giúp data scientists lựa chọn và xử lý dữ liệu đúng cách (như scaling, encoding) trong quá trình tiền xử lý.
Và đặc biệt quan trọng là Key attribute (thuộc tính khóa) – thuộc tính định danh duy nhất cho mỗi entity. Đây là thông tin quan trọng để đảm bảo tính duy nhất và liên kết giữa các bảng dữ liệu khi thực hiện phân tích.Ví dụ: StudentID cho sinh viên.
Ứng dụng trong khoa học dữ liệu: Thuộc tính dẫn xuất rất hữu ích. Chẳng hạn, từ Date of Birth, bạn có thể tính Age – một đặc trưng quan trọng để phân tích hành vi khách hàng hoặc dự đoán khách hàng rời bỏ (churn).
Yêu cầu: Mô hình hóa các thực thể và thuộc tính cho hệ thống quản lý thư viện với các yêu cầu sau:
Đáp án:
Giải thích:
Yêu cầu: Mô hình hóa các thực thể và thuộc tính cho hệ thống quản lý bán hàng online với các yêu cầu sau:
Đáp án:
Giải thích:

Quan hệ giữa các thực thể giúp bạn hiểu được cách dữ liệu tương tác với nhau.
Ví dụ: khách hàng mua sản phẩm, sản phẩm thuộc về danh mục…
Đối với data science, những mối liên hệ này là nguồn thông tin quý báu để thực hiện phân tích mạng (network analysis), tìm kiếm các pattern ẩn hoặc xây dựng các mô hình dự báo.
Ví dụ 2 : Giữa tập thực thể NHANVIEN và PHONGBAN có các liên kết
– Một nhân viên thuộc một phòng ban nào đó
– Một phòng ban có một nhân viên làm trưởng phòng
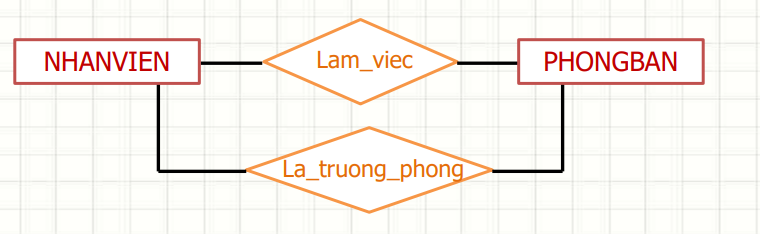
Ứng dụng trong khoa học dữ liệu: Hiểu mối quan hệ là chìa khóa để thực hiện các phép nối (joins). Ví dụ, để phân tích hành vi khách hàng, bạn có thể nối bảng Khách Hàng với bảng Giao Dịch để xem mẫu chi tiêu. Việc nắm rõ loại mối quan hệ giúp bạn chọn đúng loại nối và đảm bảo dữ liệu chính xác.

Đây là phần khó hiểu nhất nhưng cực kỳ quan trọng! Cardinality (bản số) xác định bao nhiêu entity này có thể liên kết với bao nhiêu entity khác.
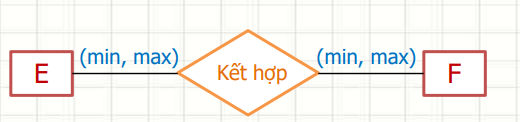
Trong mô hình ER (Entity-Relationship), ký hiệu (min, max) được sử dụng trên các đường nối của mối quan hệ để chỉ ra:
0 (không bắt buộc) hoặc 1 (bắt buộc).1 (chỉ một) hoặc n (nhiều).(0, n): Một thực thể A có thể không liên kết hoặc liên kết với nhiều thực thể B.
[Entity A] -- (0, n) -- [Entity B]
(1, 1): Mỗi thực thể A bắt buộc liên kết với đúng một thực thể B.
[Entity A] -- (1, 1) -- [Entity B]
Lưu ý: Tùy ngữ cảnh, bạn có thể gặp các ký hiệu khác như (1, n) hoặc (1, m) dựa trên yêu cầu cụ thể.
Trong sơ đồ ER, các thành phần chính bao gồm:
Quan hệ giữa Công dân và Hộ chiếu:
[Công dân] -- (1, 1) -- [Kết hợp] -- (1, 1) -- [Hộ chiếu]
Mỗi công dân có đúng một hộ chiếu, và mỗi hộ chiếu chỉ thuộc về một công dân.
Ý nghĩa: Ký hiệu này giúp mô tả chính xác cách các thực thể tương tác, hỗ trợ xây dựng Data Schema hợp lệ và tránh lỗi dữ liệu.

Mỗi thực thể E liên kết với đúng một thực thể F và ngược lại.
Ví dụ: Công dân và Hộ chiếu
[Công dân] -- (1, 1) -- [Kết hợp] -- (1, 1) -- [Hộ chiếu]
Ứng dụng Data Science: Có thể gộp dữ liệu thành một bảng để đơn giản hóa tiền xử lý và khai thác dữ liệu.
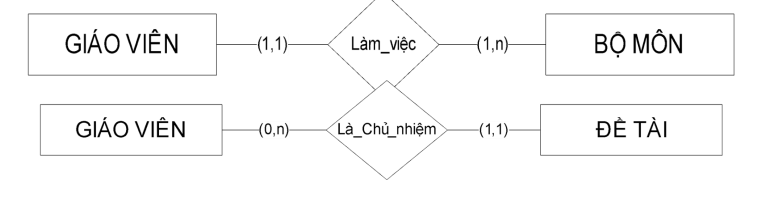
Mỗi thực thể E liên kết với nhiều thực thể F, nhưng mỗi F chỉ liên kết với một E.
Ví dụ: Phòng ban và Nhân viên
[Phòng ban] -- (1, n) -- [Thuộc] -- (1, 1) -- [Nhân viên]
Ứng dụng Data Science: Phân tích hành vi (ví dụ: Khách hàng và Đơn hàng) để dự đoán doanh thu, đảm bảo tính nhất quán dữ liệu.

Mỗi thực thể E liên kết với nhiều F và ngược lại.
Ví dụ: Sinh viên và Môn học
[Sinh viên] -- (0, n) -- [Đăng ký] -- (0, n) -- [Môn học]
Ứng dụng Data Science: Dùng trong hệ thống gợi ý (recommendation systems) hoặc phân tích mạng lưới, yêu cầu bảng trung gian.
Đặt khóa ngoại (Foreign Key) vào một trong hai bảng.
Bảng Công dân: id (PK)
Bảng Hộ chiếu: id (PK), cong_dan_id (FK → Công dân.id)
Bảng bên “nhiều” chứa khóa ngoại trỏ về bảng bên “một”.
Bảng Phòng ban: dept_id (PK)
Bảng Nhân viên: emp_id (PK), dept_id (FK → Phòng ban.dept_id)
Tạo bảng trung gian chứa khóa ngoại từ cả hai bảng.
Bảng Sinh viên: id (PK)
Bảng Môn học: id (PK)
Bảng Đăng ký: sinh_vien_id (FK → Sinh viên.id), mon_hoc_id (FK → Môn học.id)

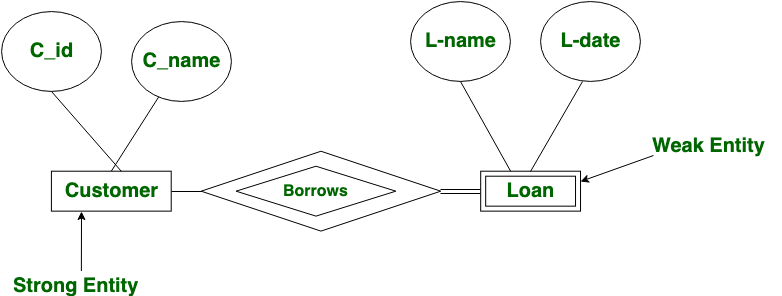
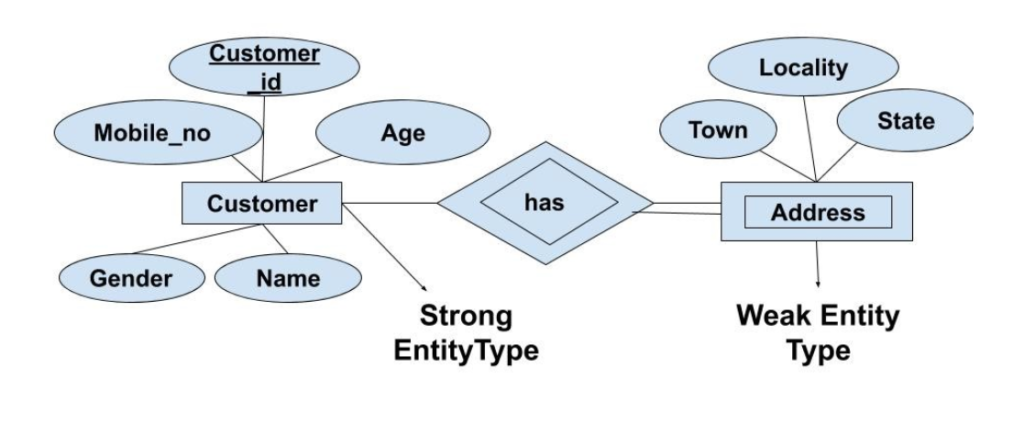
Weak Entity Set (Tập hợp thực thể yếu) là một loại thực thể trong Entity-Relationship Model (ER Model) không có khóa chính độc lập. Thay vào đó, để xác định duy nhất một thực thể trong Weak Entity Set, ta phải dựa vào khóa chính của một thực thể khác (gọi là Strong Entity Set – Tập hợp thực thể mạnh) và kết hợp với một thuộc tính phân biệt (discriminator) của chính nó.
Trong thực tế, có những đối tượng không thể tồn tại độc lập mà phải phụ thuộc vào một đối tượng khác. Sự phụ thuộc này được phản ánh trong thiết kế cơ sở dữ liệu thông qua khái niệm Weak Entity Set.
Hãy xem xét một ví dụ thực tế: Hóa đơn (Invoice) và Chi tiết hóa đơn (Detail).
Dưới đây là cách biểu diễn mối quan hệ này trong ER Diagram:
[Invoice] -- (1,1) -- [Has] -- (0,n) -- [Detail]
| |
| invoice_id (PK) | invoice_id (FK) + detail_number (PK)
| date | product
| customer_name | quantity
| price[Invoice]: Hình chữ nhật đơn (Strong Entity).[Detail]: Hình chữ nhật kép (Weak Entity).[Has]: Hình thoi kép (mối quan hệ identifying).(1,1): Mỗi Invoice có ít nhất 1 và tối đa nhiều Detail.(0,n): Mỗi Detail phải thuộc về đúng 1 Invoice.invoice_id (khóa chính), date (ngày phát hành), customer_name (tên khách hàng).invoice_id) và tồn tại độc lập.detail_number (số thứ tự chi tiết), product (sản phẩm), quantity (số lượng), price (giá).invoice_id (khóa của Invoice mà nó thuộc về).detail_number (thuộc tính phân biệt để phân biệt các chi tiết trong cùng một hóa đơn).invoice_id + detail_number.invoice_id = 001 bị xóa, tất cả các chi tiết liên quan (như detail_number = 1, 2,…) cũng phải bị xóa. Điều này phản ánh mối quan hệ “sống còn” giữa Invoice và Detail.Để dễ hình dung, hãy xem cách dữ liệu được lưu trữ trong database:
| invoice_id (PK) | date | customer_name |
|---|---|---|
| 001 | 2023-10-01 | Nguyễn Văn A |
| 002 | 2023-10-02 | Trần Thị B |
| invoice_id (FK) | detail_number (PK) | product | quantity | price |
|---|---|---|---|---|
| 001 | 1 | Laptop | 1 | 1500 |
| 001 | 2 | Mouse | 2 | 20 |
| 002 | 1 | Keyboard | 1 | 50 |
invoice_id là khóa ngoại tham chiếu đến Invoice.invoice_id + detail_number.001, các dòng 001-1 và 001-2 trong Detail cũng sẽ bị xóa.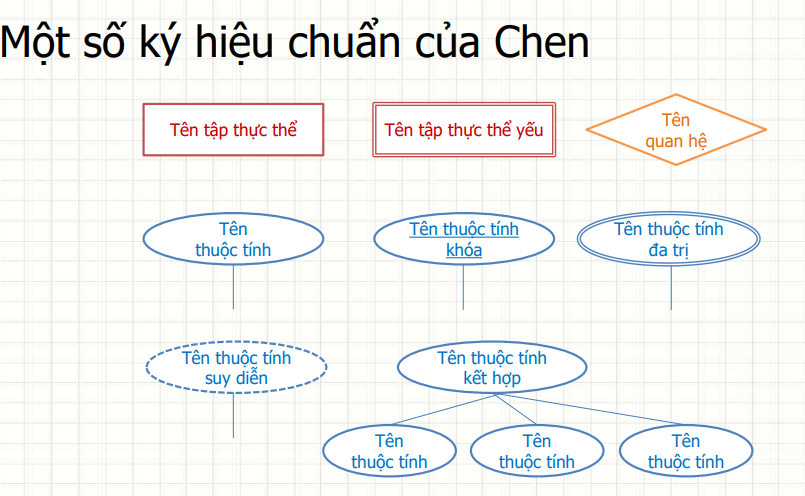
Thiết kế ER Model là một bước quan trọng trong việc xây dựng hệ thống cơ sở dữ liệu. Một mô hình ER tốt không chỉ phản ánh chính xác yêu cầu nghiệp vụ mà còn phải dễ bảo trì, tránh dư thừa dữ liệu và đảm bảo tính toàn vẹn. Dưới đây là 3 nguyên tắc vàng mà bạn cần tuân thủ:
employee_id (Mã nhân viên)name (Tên)department_name (Tên phòng ban)department_location (Địa điểm phòng ban)[Employee] -------- (1,1) -------- [WorksIn] -------- (0,n) -------- [Department]
| | |
| employee_id (PK) | | department_id (PK)
| name | | department_name
| department_id (FK) | | department_locationdepartment_name và department_location không thực sự là thuộc tính trực tiếp của Employee, mà thuộc về một entity khác: Department (Phòng ban). Nếu giữ nguyên trong Employee, dữ liệu sẽ bị dư thừa và khó bảo trì.department_id (Mã phòng ban)department_name (Tên phòng ban)department_location (Địa điểm phòng ban)department_id làm khóa ngoại (foreign key) để liên kết với Department.department_name và department_location trong Employee:department_id sẽ tự động phản ánh thay đổi.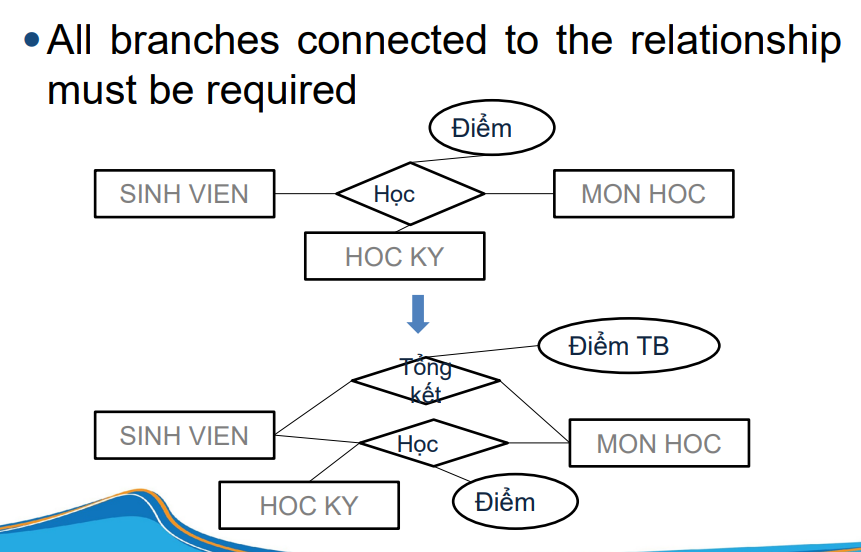
invoice_id, datedetail_id, product_name, quantity[Invoice] -------- (1,1) -------- [Has] -------- (1,n) -------- [Detail]
| | |
| invoice_id (PK) | | invoice_id (FK, PK)
| date | | detail_id (PK)
| | | product_name
| | | quantity(1,1): Mỗi Invoice phải có ít nhất 1 Detail.(1,n): Mỗi Detail phải thuộc về đúng 1 Invoice, và một Invoice có thể có nhiều Detail.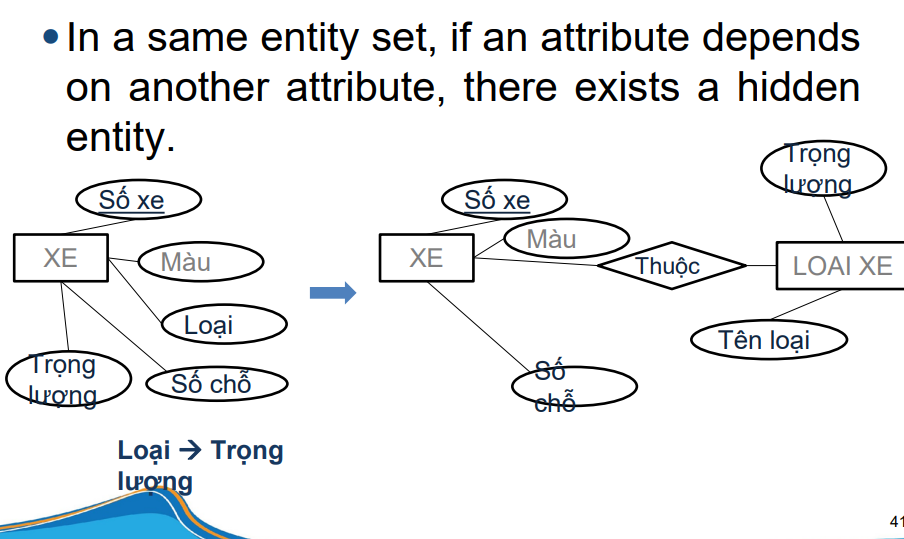
employee_id (Mã nhân viên)name (Tên)department_id (Mã phòng ban)department_name (Tên phòng ban)department_location (Địa điểm phòng ban)[Employee] -------- (1,1) -------- [WorksIn] -------- (0,n) -------- [Department]
| | |
| employee_id (PK) | | department_id (PK)
| name | | department_name
| department_id (FK) | | department_locationdepartment_name và department_location phụ thuộc vào department_id, không phải employee_id (khóa chính của Employee).department_id (PK)department_namedepartment_locationdepartment_id làm khóa ngoại.department_id. Điều này gây:
department_name và department_location lặp lại ở mỗi nhân viên.{Mã mượn, Mã sách}.{Mã đơn hàng, Mã sản phẩm}.Entity-Relationship Model không chỉ là một công cụ thiết kế, mà còn là một ngôn ngữ để chúng ta “giao tiếp” về dữ liệu một cách hiệu quả. Nắm vững ER Model giúp bạn:
“Một ER Diagram tốt còn đáng giá hơn cả ngàn dòng code!” – Loser1 😎
Các bạn thấy bài học hôm nay thế nào? Phần tiếp theo, chúng ta sẽ học cách chuyển đổi ER Model sang Relational Model – bước quan trọng để hiện thực hóa thiết kế của chúng ta trên các hệ quản trị cơ sở dữ liệu phổ biến.
Nếu có thắc mắc gì, đừng ngại comment bên dưới nhé! Loser1 luôn sẵn sàng giải đáp!
#DatabaseForDataScience #ERModel #DataModeling #LearningAIWithLoser #Loser1