Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Empowering IT & AI Insights with Losers
Empowering IT & AI Insights with Losers
Chào mừng các “loser” trở lại với vũ trụ “Database for Data Science” phiên bản “tự học không ai ép” từ Learning AI With Losers! 🎉 Lại là loser1 đây hehe..

Bạn đã bao giờ tự hỏi làm thế nào mà Amazon có thể nhớ mọi chi tiết về hàng triệu đơn hàng? Hay tại sao ngân hàng không bao giờ nhầm lẫn khi chuyển tiền giữa các tài khoản? Câu trả lời nằm ở một phát minh tuyệt vời cách đây hơn 50 năm: Mô hình dữ liệu quan hệ.
Trong hai bài viết trước, chúng ta đã xây dựng nền móng kiến thức về database. Hôm nay, chúng ta lại mò mẫm tiếp cái hành trình khám phá thế giới “dữ liệu quan hệ” 🧐 nghe có vẻ “cao siêu” nhưng thực ra cũng chỉ là mấy cái bảng với nhau thôi ấy mà! Đừng lo nếu bạn vẫn đang thấy “tẩu hỏa nhập ma” 🔥 với mấy thuật ngữ, vì chúng ta ở đây là để cùng nhau “lụt nghề” 🤣 một cách vui vẻ mà!
“Dữ liệu á? Nó như đống quần áo chưa giặt ấy. Mô hình quan hệ chính là cái tủ chia ngăn giúp chúng ta không bị ‘ngợp’ trong mớ hỗn độn đó!”
Nhấp Ngụm “Trà Đá Chanh Sả”: Nhìn Lại Quá Khứ “Hào Hùng” Của Dữ Liệu Quan Hệ

Năm 1970, một “loser” à nhầm, một nhà khoa học máy tính siêu cấp tên Edgar F. Codd (nghe tên thôi đã thấy “pro” rồi) tại IBM đã “vẽ” ra một cái ý tưởng mà sau này thay đổi cả thế giới dữ liệu. Chắc lúc đó ông ấy cũng không ngờ đứa con tinh thần của mình lại “trâu bò” đến vậy.
Hãy tưởng tượng cái thời mà dữ liệu nó cứ “tùm lum tà la” 😵 như mớ dây sạc điện thoại sau một tuần sử dụng. Muốn tìm một thông tin thôi mà các “coder” phải “vò đầu bứt tai” 🤔 viết code “toàn chưởng” 🤯 để biết nó nằm ở xó nào. Nghe thôi đã thấy “ám ảnh” 👻 rồi!
Ấy thế mà bác Codd lại nghĩ ra cái kiểu lưu trữ dữ liệu vào mấy cái bảng có liên hệ với nhau. Nghe thì có vẻ “dễ ẹc”, nhưng mà nó lại “mạnh mẽ” đến không ngờ. Đó chính là “Big Bang” của mô hình dữ liệu quan hệ đó anh em!
Từ cái ý tưởng trên giấy đó đến khi nó “bước ra ánh sáng” cũng gian nan lắm chứ bộ. Phải đến năm 1979, mấy “gã khổng lồ” Oracle mới “trình làng” cái hệ thống RDBMS thương mại đầu tiên. Lúc đó chắc họ “ăn mừng” 🎉 còn hơn cả chúng ta được “cú đêm” xem World Cup ⚽ ấy chứ!
Đến tận bây giờ, dù có bao nhiêu công nghệ “mới nổi”✨ như NoSQL hay Distributed SQL, thì cái mô hình “cổ điển” này vẫn cứ “ung dung” mà sống khỏe. Tại sao ư? Vì mấy cái nguyên tắc “cốt cán” của nó vẫn “chất”: dữ liệu phải “gọn gàng”✅, “đáng tin” và “hỏi gì cũng trả lời” được. Giống như mấy ông “loser” học lại bài cũ vẫn nhớ kiến thức căn bản ấy! 😉
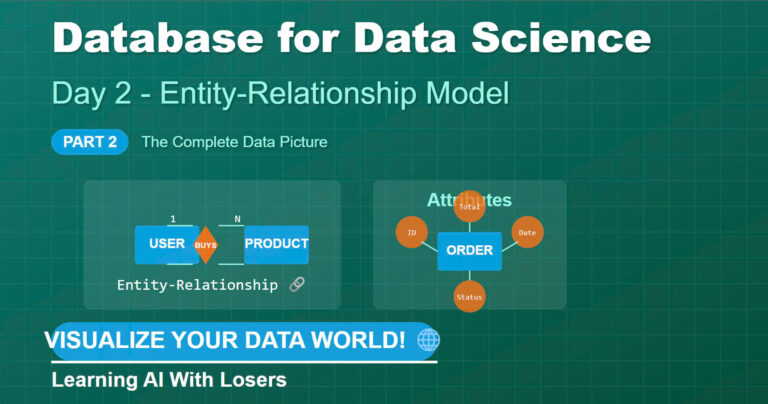
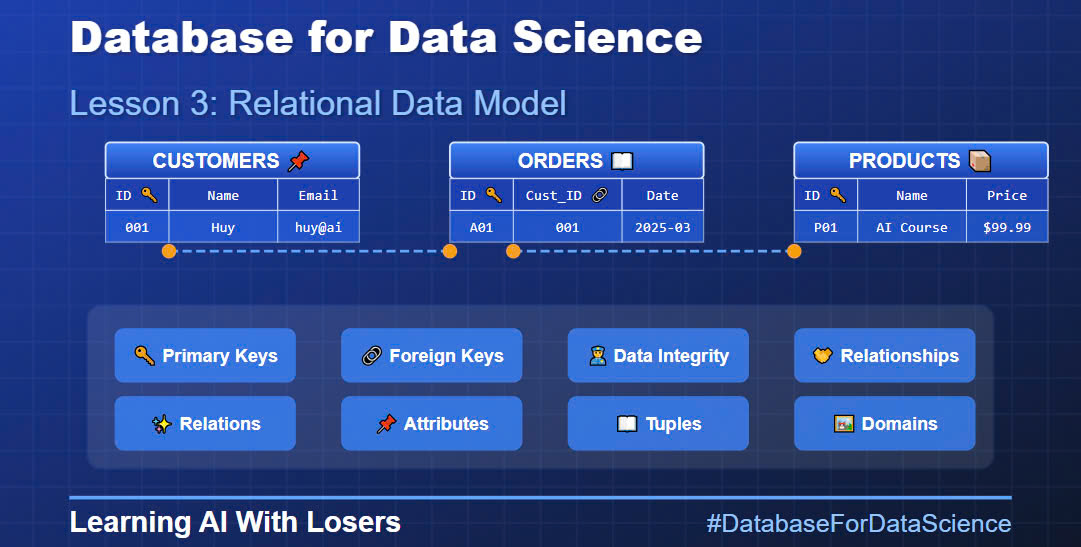
Hãy bắt đầu với khái niệm nền tảng: Relations hay Tables (Bảng).
Tưởng tượng bạn đang quản lý một tiệm bánh nhỏ. Mỗi ngày, bạn có nhiều khách hàng đến mua với các đơn hàng khác nhau. Làm thế nào để theo dõi tất cả thông tin này?
Trong mô hình quan hệ, bạn sẽ tạo các bảng riêng biệt:
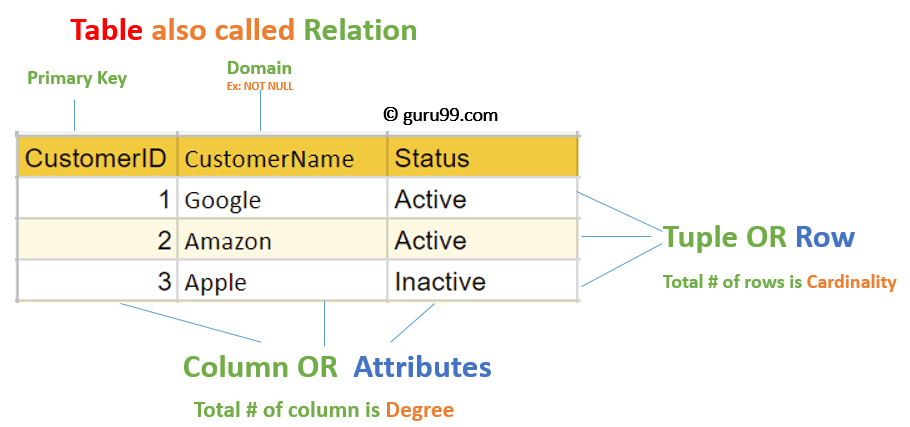
Cứ hình dung “relation” hay “table” (bảng) nó giống như một cái bảng Excel mà bạn hay dùng ấy. Nhưng mà nó có mấy cái “luật ngầm” mà bạn phải nhớ:

Một relation giống như một hộp sắp xếp ngăn nắp – mỗi thứ đều có vị trí riêng, và bạn luôn biết chính xác nơi tìm kiếm thông tin mình cần.
“Attributes” hay cột nó giống như mấy cái “nhãn dán” để mô tả đặc điểm của dữ liệu trong bảng.
Ví dụ thực tế: Trong bảng NHÂN_VIÊN của một công ty:
Tưởng tượng bạn đang mô tả một người. Bạn không thể nói “Tuổi của anh ấy là một con mèo” – điều đó vô nghĩa phải không? Tương tự, trong mô hình quan hệ, mỗi cột phải tuân theo một domain ( cái này loser1 sẽ giải thích ở dưới nha iu iu , loser1 gay vãi c…c sorry ae ) – tập các giá trị hợp lệ. Cột NgaySinh chỉ có thể chứa ngày tháng, không thể là văn bản hay âm thanh.
Định nghĩa không hình thức: Domain là tập hợp các giá trị mà một thuộc tính có thể nhận. Nó giống như kiểu “luật chơi” cho từng cột vậy. ( Hé lộ xíu cho ae )
“Tuples” hay hàng chính là nơi mà dữ liệu thực tế được “kể” lại 🗣️. Mỗi hàng đại diện cho một “thực thể” 👤 cụ thể. Kiểu hàng 1 là thông tin của loser1 , hàng 2 là thông tin của loser2 vậy đó có hiểu không ?
Trong bảng HỌC_SINH:
| MaHS | HoTen | Lop | DiemTB |
|------|-----------------|------|--------|
| 001 | Nguyễn Văn An | 10A1 | 8.5 |
| 002 | Trần Thị Bình | 10A2 | 9.0 |
| 003 | Lê Minh Châu | 10A1 | 7.5 |
Mỗi hàng đại diện cho một học sinh cụ thể với đầy đủ thông tin. Hàng đầu tiên không phải là “Nguyễn Văn An và bạn bè của cậu ấy” – nó chỉ về một học sinh duy nhất.
Mấy ông “tuples” này cũng có “tính cách” riêng đó:

Định nghĩa không hình thức: “Domain” giống như cái “khuôn khổ” 🖼️ để xác định những giá trị nào là “chấp nhận được” 👍 cho một thuộc tính.Ví dụ, cột “Giới tính” thì domain của nó thường là {“Nam”, “Nữ”, “Khác”}. Bạn không thể nhập “Con mèo” vào cột này được.
Định nghĩa hình thức: Cho một lược đồ quan hệ R(A1, A2, …, An), domain của thuộc tính Ai, ký hiệu là dom(Ai), là tập hợp tất cả các giá trị có thể xuất hiện trong cột Ai của bất kỳ thể hiện hợp lệ nào của quan hệ R. Nói một cách “khô khan” thì nó là tập hợp các giá trị mà thuộc tính đó được phép nhận.
Ví dụ sinh động:
Domains giống như những chiếc hộp với nhãn dán rõ ràng. Bạn không thể đặt một chiếc giày vào hộp đựng trứng, đúng không? Cũng vậy, bạn không thể nhập “Mèo” vào cột “Nhóm máu”.
Việc xác định domain giúp chúng ta tránh được những sai sót “ngớ ngẩn” 🤔 khi nhập liệu.

Đây là phần “hóc búa” một chút, anh em nào thấy “lú” thì cứ từ từ nhé! Không ae khỏi xem cũng được …. loser1 ghét toán , loser1 hận toán 😂
Một quan hệ r(R) của một lược đồ R(A1, A2, …, An) được định nghĩa một cách hình thức như sau:
Trong đó:
Nhận xét “toán học”: r(R) là một tập con của tích Descartes của tất cả các miền: r(R) ⊆ (dom(A1) × dom(A2) × … × dom(An)).
Giá trị thứ i của bộ t có thể được biểu diễn bằng t.Ai (truy cập theo tên thuộc tính) hoặc t[i] (truy cập theo vị trí).
Các khái niệm – Lược đồ của một quan hệ (Lược đồ Quan hệ):
Một lược đồ của một Quan hệ R, được biểu diễn bởi R(A1, A2, …, An), bao gồm:
Mỗi thuộc tính Ai sẽ nhận các giá trị thuộc về một miền giá trị nhất định, ký hiệu là dom(Ai) (ví dụ: dom(MÃKHOA) có thể là tập hợp các chuỗi ký tự, dom(NĂMTL) có thể là tập hợp các số nguyên).

Bậc của lược đồ chính là số lượng thuộc tính mà nó có.
Ví dụ: Lược đồ KHOA (MÃKHOA, TÊNKHOA, NĂMTL, PHÒNG, ĐIỆNTHOẠI, TRƯỞNGKHOA, NGÀYNHẬNCHỨC).
Các khái niệm – Lược đồ cơ sở dữ liệu quan hệ:
Một lược đồ cơ sở dữ liệu quan hệ sẽ bao gồm một tập hợp các lược đồ quan hệ:
S = {R1, R2, …, Rn}
Ví dụ, một lược đồ cơ sở dữ liệu có thể bao gồm các lược đồ sau:
Các khái niệm – Ghi chú “Nhỏ Nhưng Có Võ”:
“Keys” là một khái niệm “xịn sò” ✨ hơn một chút, nhưng nó lại đóng vai trò cực kỳ quan trọng trong việc đảm bảo tính toàn vẹn và mối quan hệ giữa các bảng.

Hãy xem xét một tình huống thực tế: Trong một lớp học có hai bạn cùng tên “Nguyễn Thị Hương”. Làm thế nào để phân biệt? Đó là lúc primary key xuất hiện!
Primary key giống như số CMND/CCCD – nó đảm bảo mỗi người là duy nhất. Trong bảng SINH_VIÊN, MaSV là primary key:
| MaSV | HoTen | NgaySinh |
|--------|-------------------|------------|
| SV0001 | Nguyễn Thị Hương | 15/04/2000 |
| SV0002 | Nguyễn Thị Hương | 22/07/2001 |
Dù hai sinh viên trùng tên, chúng ta vẫn phân biệt được họ nhờ MaSV.
“Foreign key” là “cầu nối” 🌉 giữa các bảng. Nó là một hoặc một nhóm thuộc tính trong một bảng mà nó tham chiếu đến “primary key” 🔑 của một bảng khác. Nhờ có “foreign key” mà chúng ta có thể thiết lập mối quan hệ 🤝 giữa các bảng.

Ví dụ thực tế từ một trường học:
GIÁO_VIÊN:
| MaGV | HoTen | Bộ môn |
|------|-----------------|-------------|
| GV01 | Trần Minh Châu | Toán |
| GV02 | Lê Hoàng Nam | Lý |
LỚP_HỌC:
| MaLop | TenLop | GiaoVienChuNhiem |
|-------|--------|------------------|
| L01 | 10A1 | GV01 |
| L02 | 10A2 | GV02 |
Khi nhìn vào lớp 10A1, tôi biết ngay cô Trần Minh Châu là giáo viên chủ nhiệm – đó là sức mạnh của mối quan hệ!
Điều thú vị là foreign key có thể chứa giá trị NULL. Ví dụ, một lớp học mới thành lập có thể chưa có giáo viên chủ nhiệm.
Định nghĩa không hình thức: Khóa ngoại là một hoặc một tập hợp các thuộc tính trong một bảng mà giá trị của nó phải khớp với một giá trị tồn tại trong khóa chính 🔑 của một bảng khác (hoặc có thể là NULL nếu thuộc tính đó cho phép NULL). Nó giống như “địa chỉ nhà” 🏠 để liên kết đến thông tin ở bảng khác.
Định nghĩa hình thức: Cho hai lược đồ quan hệ R1(A1, A2, …, An) với khóa chính PKR1 và R2(B1, B2, …, Bm). Một tập hợp các thuộc tính FK là tập con của {B1, B2, …, Bm} được gọi là khóa ngoại tham chiếu đến R1 nếu:
Các thuộc tính trong FK có cùng miền với các thuộc tính tương ứng trong PKR1.
Với mọi bộ t2 trong thể hiện của R2, giá trị của t2(FK) phải bằng giá trị của t1(PKR1) cho một số bộ t1 trong thể hiện của R1, hoặc t2(FK) là NULL (nếu các thuộc tính trong FK cho phép NULL).

Để đảm bảo dữ liệu của chúng ta luôn “sạch đẹp” ✨ và “đáng tin” ✅, chúng ta cần phải có những “luật lệ” 📜 gọi là “integrity constraints” (ràng buộc toàn vẹn). Chúng giống như hàng rào bảo vệ, ngăn chặn việc nhập dữ liệu không hợp lệ và duy trì chất lượng của thông tin được lưu trữ.
Mấy cái ràng buộc này nó giống như mấy anh “bảo vệ” 🛡️ đứng ở cổng của từng cột dữ liệu, chỉ cho phép những giá trị “hợp lệ” ✅ mới được “vào” 🚶. Chúng ta đã nói ở trên rồi nên không nhắc lại nữa nhé! 😉
Ứng dụng trong SQL:
CREATE TABLE Học_Sinh (
MãHS VARCHAR(10) PRIMARY KEY,
Tên VARCHAR(50) NOT NULL,
Tuổi INT CHECK (Tuổi >= 6 AND Tuổi <= 18),
ĐiểmTrungBình DECIMAL(3,1) CHECK (ĐiểmTrungBình >= 0 AND ĐiểmTrungBình <= 10),
Email VARCHAR(100) CHECK (Email LIKE '%@%.%'),
LớpHọc VARCHAR(10) CHECK (LớpHọc IN ('10A', '10B', '11A', '11B', '12A', '12B'))
);
Domain constraints hoạt động như một “bảo vệ cửa” tại mỗi cột dữ liệu, ngăn chặn những giá trị không hợp lệ ngay từ khi chúng cố gắng xâm nhập vào cơ sở dữ liệu. Nhờ vậy, bạn sẽ không bao giờ phải đối mặt với những trường hợp phi lý như học sinh 50 tuổi hay điểm thi -5 điểm.

Cái này thì liên quan đến “primary key” 🔑. Nó đảm bảo rằng mọi bảng đều phải có một “primary key” và không có giá trị nào trong “primary key” được phép là NULL ❌. Nếu không có “primary key” hoặc có giá trị NULL thì coi như mỗi hàng không có “tên tuổi” 👤 gì cả, rất dễ gây ra nhầm lẫn ❓.
CREATE TABLE Tài_Khoản (
SốTàiKhoản VARCHAR(16) PRIMARY KEY,
TênChủTàiKhoản VARCHAR(100) NOT NULL,
SốDư DECIMAL(12,2) NOT NULL DEFAULT 0.00,
NgàyMởTàiKhoản DATE NOT NULL );
Khi hệ thống áp dụng entity integrity, mọi giao dịch đều được gắn với một tài khoản xác định, giúp theo dõi dòng tiền chính xác và tránh mất mát tài chính.
Entity integrity là nền tảng cho việc xác định và truy xuất dữ liệu một cách đáng tin cậy. Khi mỗi bản ghi đều có một “căn cước” riêng biệt và không thể trùng lặp, việc quản lý và khai thác dữ liệu trở nên đơn giản và chính xác hơn nhiều.

Cái này thì liên quan đến “foreign key” 🔗. Nó đảm bảo rằng mối quan hệ 🤝 giữa các bảng luôn “khăng khít” . Giá trị của “foreign key” ở một bảng phải khớp với giá trị của “primary key” 🔑 ở bảng mà nó tham chiếu đến (hoặc có thể là NULL). Nếu không có cái ràng buộc này thì có thể xảy ra tình trạng “con rơi con rớt” – tức là có dữ liệu ở bảng này nhưng lại không tìm thấy thông tin liên quan ở bảng kia 🤔.
CREATE TABLE Đơn_Hàng (
MãĐơnHàng INT PRIMARY KEY,
MãKháchHàng INT NOT NULL,
NgàyĐặt DATE NOT NULL,
TổngTiền DECIMAL(10,2) NOT NULL,
FOREIGN KEY (MãKháchHàng) REFERENCES Khách_Hàng(MãKháchHàng)
ON DELETE RESTRICT
ON UPDATE RESTRICT
);
Tình huống thực tế: Khi một nhân viên cố gắng xóa thông tin của khách hàng “Nguyễn Văn A” (MãKH = 1001) từ bảng Khách_Hàng, nhưng khách hàng này đã có 5 đơn hàng trong bảng Đơn_Hàng.
Kết quả: Hệ thống sẽ hiển thị thông báo lỗi: “Không thể xóa khách hàng vì đã có đơn hàng liên quan.”
Lợi ích: Ngăn chặn việc mất dữ liệu quan trọng về lịch sử đơn hàng, đảm bảo dữ liệu được lưu trữ đầy đủ.
CREATE TABLE Chi_Tiết_Đơn_Hàng (
MãChiTiết INT PRIMARY KEY,
MãĐơnHàng INT NOT NULL,
MãSảnPhẩm INT NOT NULL,
SốLượng INT NOT NULL,
FOREIGN KEY (MãĐơnHàng) REFERENCES Đơn_Hàng(MãĐơnHàng)
ON DELETE CASCADE
);
Tình huống thực tế: Khi phát hiện một đơn hàng giả mạo (MãĐH = 5001) cần phải xóa khỏi hệ thống.
Kết quả: Khi xóa đơn hàng này từ bảng Đơn_Hàng, tất cả các bản ghi liên quan trong bảng Chi_Tiết_Đơn_Hàng cũng sẽ tự động bị xóa.
Lợi ích: Duy trì tính nhất quán dữ liệu, tránh tình trạng “chi tiết đơn hàng mồ côi” không gắn với đơn hàng nào.
CREATE TABLE Nhân_Viên (
MãNV INT PRIMARY KEY,
Tên VARCHAR(50) NOT NULL,
MãPhòngBan INT,
FOREIGN KEY (MãPhòngBan) REFERENCES Phòng_Ban(MãPhòngBan)
ON DELETE SET NULL
);
Tình huống thực tế: Công ty tiến hành tái cơ cấu và giải thể phòng Marketing (MãPB = 3).
Kết quả: Khi xóa phòng Marketing khỏi bảng Phòng_Ban, tất cả nhân viên thuộc phòng này sẽ có MãPhòngBan được đặt thành NULL, chỉ ra rằng họ “chưa được phân công” vào phòng ban nào.
Lợi ích: Giữ lại thông tin nhân viên để có thể dễ dàng phân công lại họ vào các phòng ban khác trong tương lai.
CREATE TABLE Sản_Phẩm (
MãSP INT PRIMARY KEY,
Tên VARCHAR(100) NOT NULL,
MãDanhMục INT DEFAULT 1,
FOREIGN KEY (MãDanhMục) REFERENCES Danh_Mục(MãDanhMục)
ON DELETE SET DEFAULT
);
Tình huống thực tế: Cửa hàng quyết định loại bỏ danh mục “Sách giáo khoa” (MãDM = 5).
Kết quả: Khi xóa danh mục này, tất cả sản phẩm thuộc danh mục “Sách giáo khoa” sẽ được chuyển sang danh mục mặc định “Chưa phân loại” (MãDM = 1).
Lợi ích: Đảm bảo không có sản phẩm nào bị “thất lạc” trong hệ thống, luôn có một danh mục để phân loại.
| Thao Tác trên Bảng Cha | Tùy Chọn Xử Lý Ràng Buộc | Hành Vi ở Bảng Con | Hậu Quả Tiềm Ẩn |
| Xóa Bản Ghi | REJECT (RESTRICT) | Ngăn chặn thao tác. | Đảm bảo không có bản ghi mồ côi nhưng có thể hạn chế các thao tác xóa cần thiết. |
| Xóa Bản Ghi | CASCADE | Các bản ghi liên quan trong bảng con cũng bị xóa. | Duy trì tính nhất quán nhưng có thể dẫn đến mất dữ liệu không mong muốn nếu không được quản lý cẩn thận. |
| Xóa Bản Ghi | SET NULL | Giá trị foreign key trong các bản ghi con liên quan được đặt thành NULL (nếu cột đó cho phép NULL). | Cắt đứt mối quan hệ nhưng vẫn giữ lại bản ghi con. |
| Xóa Bản Ghi | SET DEFAULT | Giá trị foreign key trong các bản ghi con liên quan được đặt thành giá trị mặc định (nếu có). | Cung cấp một liên kết hợp lệ thay thế. |
| Cập Nhật Primary Key | REJECT (RESTRICT) | Ngăn chặn thao tác. | Đảm bảo không có liên kết bị hỏng nhưng có thể cản trở các thao tác cập nhật cần thiết. |
| Cập Nhật Primary Key | CASCADE | Các giá trị foreign key tương ứng trong các bản ghi con liên quan được tự động cập nhật. | Duy trì tính nhất quán giữa các bảng. |
| Cập Nhật Primary Key | SET NULL | Giá trị foreign key trong các bản ghi con liên quan được đặt thành NULL (nếu cột đó cho phép NULL). | Cắt đứt mối quan hệ. |
| Cập Nhật Primary Key | SET DEFAULT | Giá trị foreign key trong các bản ghi con liên quan được đặt thành giá trị mặc định (nếu có). | Cung cấp một liên kết hợp lệ thay thế. |
Tính toàn vẹn tham chiếu là yếu tố then chốt để duy trì tính nhất quán và chính xác giữa các bảng có liên quan trong cơ sở dữ liệu. Các tùy chọn xử lý khác nhau cung cấp sự linh hoạt dựa trên yêu cầu cụ thể của ứng dụng.
Relations and Tuples: Mấy Cái Đặc Điểm “Nhỏ Mà Có Võ” 💪
Để nhớ lâu hơn về “relations” và “tuples”, hãy “khắc cốt ghi tâm” ❤️ mấy cái đặc điểm này nhé:
Relations (Bảng):
Tuples (Hàng):
Những đặc điểm này là nền tảng cho định nghĩa chính thức của mô hình quan hệ, đảm bảo tính nhất quán logic và tính toàn vẹn dữ liệu của nó. Việc thứ tự của các hàng không quan trọng cho phép cơ sở dữ liệu tối ưu hóa việc thực hiện truy vấn mà không ảnh hưởng đến ý nghĩa logic của dữ liệu. Tính duy nhất của các tuples đảm bảo rằng mỗi bản ghi đại diện cho một đối tượng riêng biệt.

Mô hình dữ liệu quan hệ được ứng dụng rộng rãi trong nhiều lĩnh vực, và khoa học dữ liệu không phải là ngoại lệ. Hãy xem xét một vài ví dụ về cách mô hình này được sử dụng trong thực tế :
Trong mỗi ví dụ này, mối quan hệ giữa các bảng (thông qua foreign keys) cho phép chúng ta kết hợp các tập dữ liệu khác nhau để thực hiện các phân tích phức tạp, chẳng hạn như kết hợp dữ liệu khách hàng với lịch sử mua hàng của họ để xác định các mẫu mua hàng. Mô hình quan hệ cung cấp một cách có cấu trúc để tổ chức các loại dữ liệu đa dạng mà chúng ta thường gặp trong khoa học dữ liệu, tạo điều kiện thuận lợi cho việc truy vấn và phân tích hiệu quả.
Một trong những lý do khiến mô hình quan hệ vẫn “hot hòn họt” 🔥 trong khoa học dữ liệu là vì sự phổ biến của SQL (Structured Query Language) 💬 – cái ngôn ngữ “thần thánh” để “nói chuyện” với các cơ sở dữ liệu quan hệ. Biết SQL thì bạn có thể “moi móc” , “xào nấu” dữ liệu một cách “chuyên nghiệp” 😎.
Ngoài ra, mô hình quan hệ còn hỗ trợ các thuộc tính ACID (Atomicity, Consistency, Isolation, Durability) 💪, đảm bảo dữ liệu luôn “chắc chắn như bắp” .
Tuy rằng mấy cái NoSQL cũng đang nổi lên như “diều gặp gió” , nhưng mô hình quan hệ vẫn là “trùm cuối” cho những dữ liệu có cấu trúc rõ ràng và cần phân tích “kỹ càng” 🧐.

Chúng ta vừa cùng nhau khai phá mô hình dữ liệu quan hệ, một viên gạch nền tảng trong thế giới khoa học dữ liệu. Nếu bạn đã theo dõi đến đây, xin chúc mừng! Bạn không chỉ tiếp thu kiến thức mà còn đang rèn luyện tư duy dữ liệu một cách bài bản. 🚀
Nhưng đừng dừng lại ở lý thuyết! Kiến thức chỉ thực sự có ý nghĩa khi bạn áp dụng nó vào thực tế. Hãy tiếp tục mày mò, thực hành, thử nghiệm, và đừng ngại đặt câu hỏi. AI và Data Science là cuộc chơi của những kẻ dám kiên trì, dám sai và dám sửa.
🔜 Trong bài viết tiếp theo, chúng ta sẽ tiếp tục hành trình với một chủ đề cực kỳ thú vị, giúp bạn tiến xa hơn trên con đường master Database for Data Science. Bạn đã sẵn sàng chưa? Hẹn gặp lại trong bài viết tiếp theo! 💡🔥
📢 Theo dõi Learning AI With Losers ngay để không bỏ lỡ bất kỳ bài viết nào! 🚀💙

🔖 Hashtags:
#LearningAIWithLosers #DatabaseForDataScience #RelationalModel #SQL #DataScience