Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

Empowering IT & AI Insights with Losers
Empowering IT & AI Insights with Losers

Loser1 from Learning AI with Loser 🚀
Chào mọi người! 😄 Mình là Loser1 từ Learning AI with Losers, và hôm nay là một bước ngoặt quan trọng trong hành trình học hỏi của mình! 🚀 Sau một thời gian dài chiến đấu với những bài Leetcode Daily Challenge (một series đầy thử thách nhưng cũng rất thú vị), mình quyết định tạm dừng lại để bắt đầu một series mới mang tên “Database for Data Science”! 🎉
Vâng, chính xác! Đây sẽ là khởi đầu của một chương mới, và cũng là sự kết thúc của những thử thách Leetcode Daily. Nhưng đừng lo, mình vẫn sẽ tiếp tục luyện tập và học hỏi! 💪 Trong series này, mình sẽ đưa các bạn cùng mình khám phá thế giới của Cơ Sở Dữ Liệu (CSDL), một chủ đề cực kỳ quan trọng trong Data Science và Machine Learning. Chắc chắn bạn sẽ thấy rằng, nếu hiểu đúng về CSDL, bạn sẽ xây dựng được những hệ thống xử lý dữ liệu cực kỳ mạnh mẽ và hiệu quả! 🔥
Vậy nên, hãy chuẩn bị tinh thần cho những bài viết cực kỳ chi tiết và đầy đủ, với không ít icon, cảm xúc, và những kiến thức “sâu sắc” mà chúng ta sẽ cùng nhau chinh phục! 🌟
Cùng theo dõi và khám phá nhé! 🚀

Cơ sở dữ liệu này quản lý thông tin về sinh viên, môn học, giảng viên và điểm số.
| Mã SV | Họ Tên | Ngày Sinh | Địa Chỉ | Mã Lớp |
|---|---|---|---|---|
| SV001 | Nguyễn Văn A | 2000-02-15 | Hà Nội | L01 |
| SV002 | Trần Thị B | 1999-06-10 | TP. HCM | L02 |
| Mã MH | Tên Môn Học | Số Tín Chỉ |
|---|---|---|
| MH101 | Cơ Sở Dữ Liệu | 3 |
| MH102 | Lập Trình C++ | 4 |
| Mã SV | Mã MH | Mã GV | Điểm |
|---|---|---|---|
| SV001 | MH101 | GV001 | 8.0 |
| SV002 | MH102 | GV002 | 7.5 |
✅ Dữ liệu có tổ chức: Không phải chỉ là một tập hợp ngẫu nhiên các dữ liệu.

✅ Có khả năng chia sẻ: Nhiều người dùng có thể truy cập đồng thời.
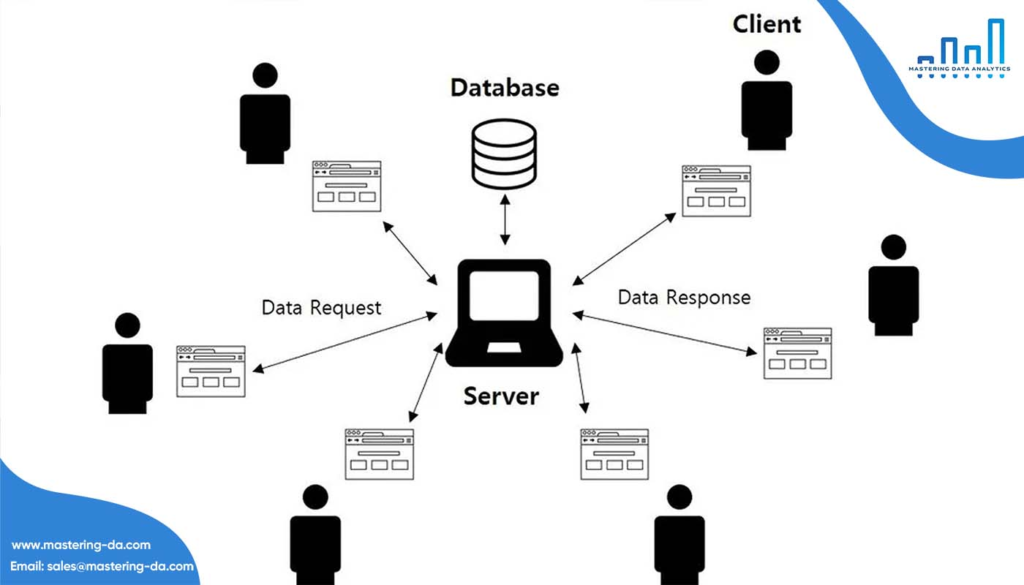
✅ Bảo mật và toàn vẹn dữ liệu: Ngăn chặn truy cập trái phép và đảm bảo tính chính xác.

✅ Tối ưu hóa truy vấn dữ liệu: Cho phép thao tác nhanh chóng và hiệu quả.

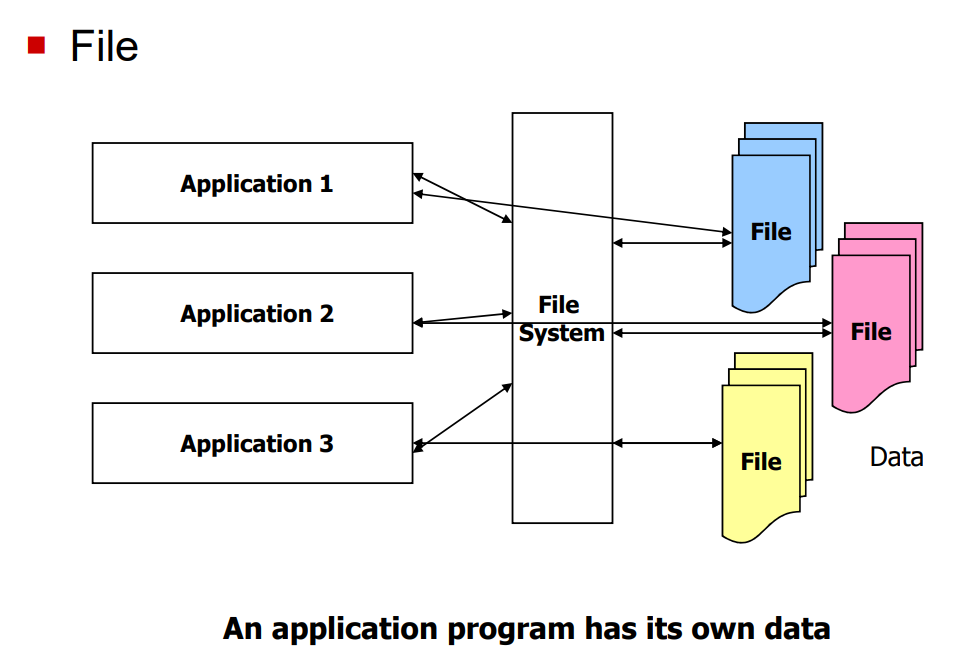
1️⃣ Giai đoạn 1: Hệ thống tập tin (File System)
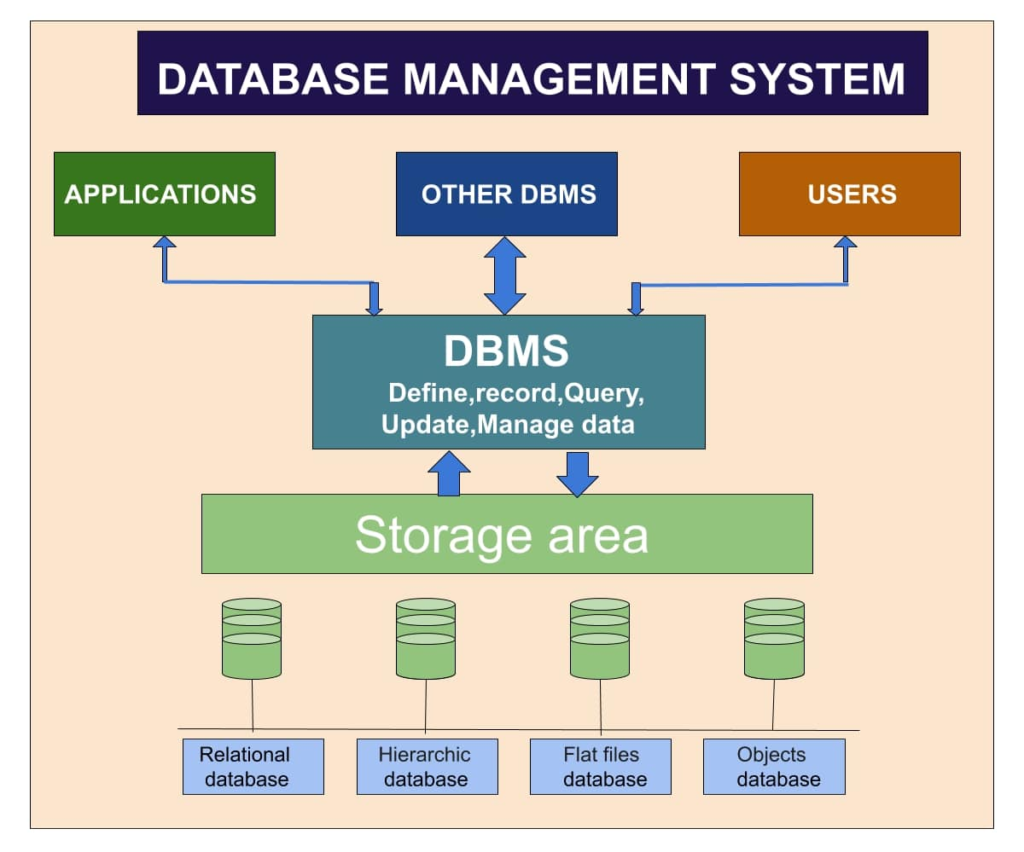
2️⃣ Giai đoạn 2: Hệ quản trị cơ sở dữ liệu (DBMS – Database Management System)
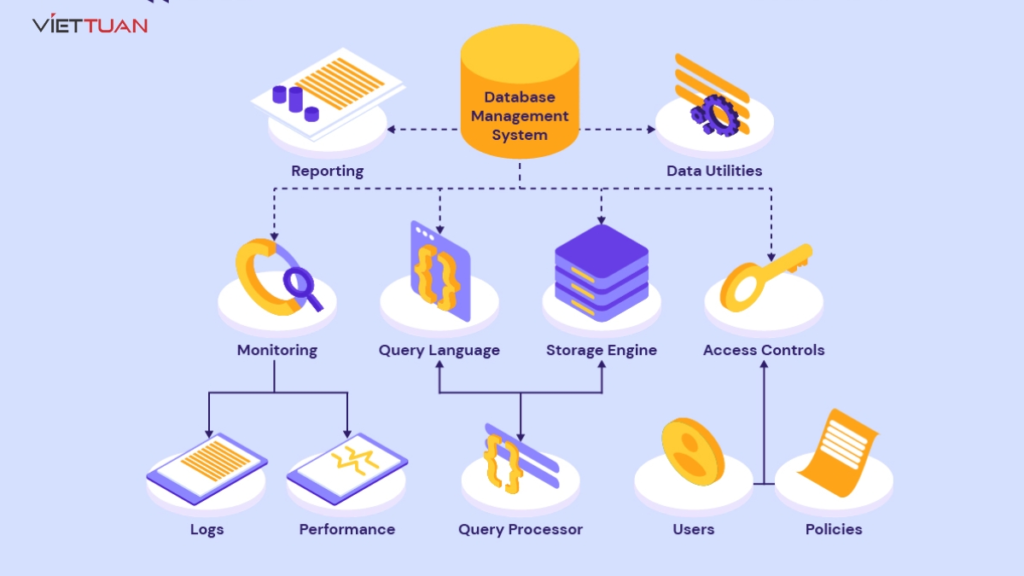
DBMS là gì? – Hệ thống phần mềm giúp quản lý, truy xuất và thao tác trên cơ sở dữ liệu.
Trước đây, dữ liệu được lưu trữ dưới dạng tập tin rời rạc. Điều này gây ra nhiều vấn đề như:
💡 DBMS được phát triển để khắc phục những hạn chế trên, giúp quản lý dữ liệu một cách tập trung và hiệu quả hơn.
Xây dựng CSDL: Tạo, thiết lập và tổ chức dữ liệu.
Thao tác trên dữ liệu: Thêm, sửa, xóa, truy vấn dữ liệu một cách hiệu quả.
Kiểm soát truy xuất: Đảm bảo bảo mật dữ liệu và phân quyền người dùng.
1. Định nghĩa dữ liệu: Xác định cấu trúc, kiểu dữ liệu và ràng buộc.
2. Lưu trữ dữ liệu: Lưu dữ liệu vào bộ nhớ phụ (disk, cloud, v.v.).
3. Truy vấn và báo cáo: Lấy dữ liệu theo yêu cầu và xuất báo cáo.
Ban đầu, DBMS chủ yếu sử dụng hai mô hình:
🔹 Ngày nay, DBMS hiện đại sử dụng mô hình quan hệ (Relational Model) với các hệ thống như MySQL, PostgreSQL, Oracle.
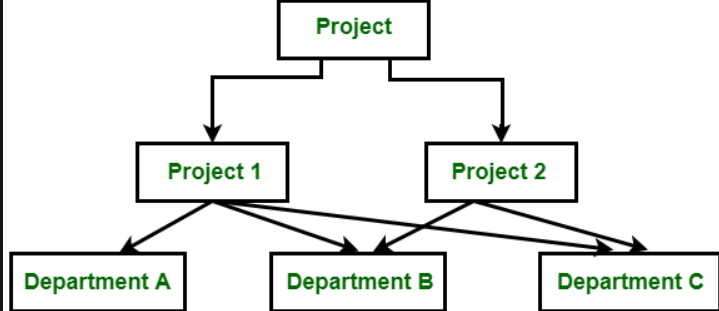
Ảnh minh họa của Network Data Model :
Ảnh minh họa của mô hình Hierarchical Data Model:
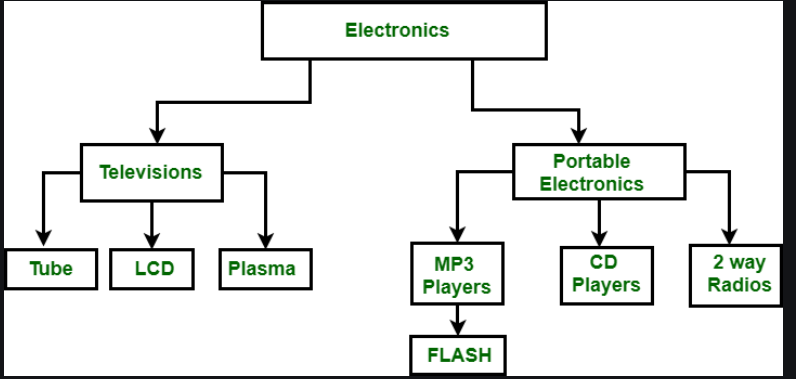
Link minh họa để tìm hiểu thêm : https://www.geeksforgeeks.org/difference-between-hierarchical-and-network-data-model/
3️⃣ Giai đoạn 3: Cơ sở dữ liệu hiện đại (Cloud Database, Big Data, NoSQL)
CSDL không chỉ chứa dữ liệu, mà còn lưu trữ **mô tả về dữ liệu** (metadata).
📌 Quan trọng với Data Science: Metadata giúp Data Scientists hiểu được **cấu trúc, kiểu dữ liệu** trước khi xử lý dữ liệu.
**Cấu trúc CSDL độc lập với chương trình**, giúp **dễ bảo trì và nâng cấp** mà không cần sửa đổi code.
📌 **Data Engineering cần biết**: Khi schema thay đổi, ETL pipelines và queries có thể bị ảnh hưởng, cần kiểm tra kỹ metadata!
**Người dùng chỉ thấy dữ liệu ở mức logic**, không cần biết cách dữ liệu được lưu trữ thực tế.
📌 **Ứng dụng trong Machine Learning**: Data Scientists có thể truy vấn dữ liệu mà không cần lo về cách nó được lưu trữ vật lý.
**Đảm bảo dữ liệu luôn chính xác và không bị trùng lặp** khi nhiều người cùng thao tác.
📌 **Cực kỳ quan trọng cho Data Science**: Nếu dữ liệu không nhất quán, mô hình ML sẽ bị sai lệch!
**Mỗi người dùng có thể có “khung nhìn” (view) riêng**, chỉ truy vấn được phần dữ liệu cần thiết.
📌 **Ứng dụng trong phân tích dữ liệu**: Data Analysts có thể tạo views cho từng nhóm người dùng mà không ảnh hưởng đến dữ liệu gốc.
✅ Lưu trữ & quản lý dữ liệu: Dữ liệu được tổ chức giúp phân tích hiệu quả.
✅ Xử lý dữ liệu lớn: Data Science thường làm việc với hàng triệu dữ liệu, cần các DBMS mạnh mẽ.
✅ Truy xuất dữ liệu nhanh: Sử dụng SQL để lấy dữ liệu cần thiết cho mô hình AI.
✅ Tích hợp AI với Database: Hỗ trợ tìm kiếm thông minh, phân tích dữ liệu lớn.
🔹 So sánh Database trong Data Science vs Backend vs Data Engineering:
| Lĩnh vực | Vai trò của Database |
|---|---|
| Data Science | Truy vấn & phân tích dữ liệu, dùng SQL/NoSQL |
| Backend Dev | Lưu trữ và xử lý dữ liệu của ứng dụng web |
| Data Engineering | Thiết kế & tối ưu hóa pipeline dữ liệu |
Dưới đây là phiên bản đầy đủ hơn với nhiều icon và cảm xúc sinh động giúp bạn dễ hình dung hơn:
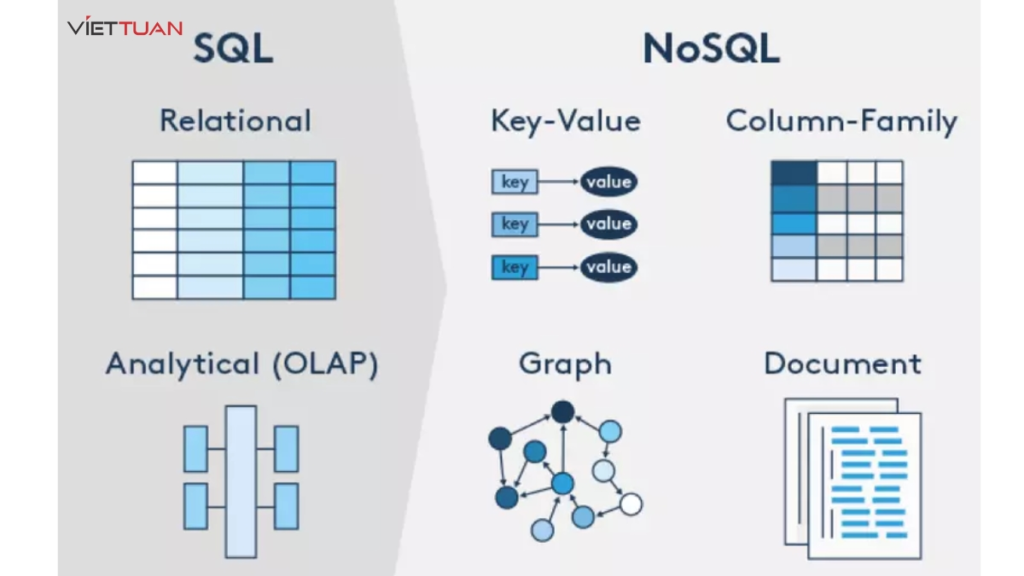
Các hệ quản trị CSDL Phổ biến :

Định Nghĩa Hệ Quản Trị Cơ Sở Dữ Liệu
💡 Định nghĩa:
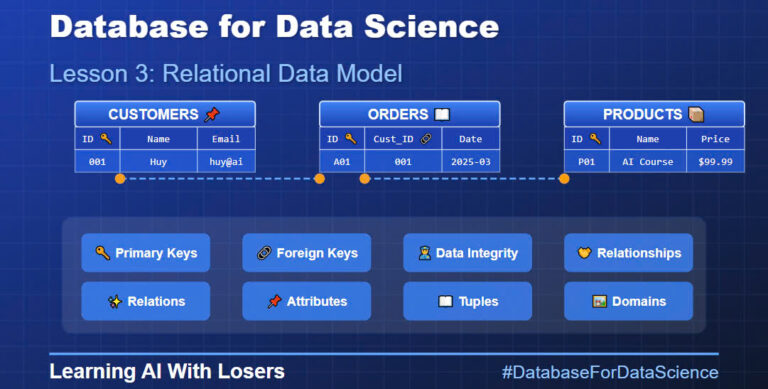
Hệ quản trị CSDL quan hệ (Relational Database Management System – RDBMS) lưu trữ dữ liệu theo dạng bảng (table), với các hàng (row) và cột (column). Các bảng này có thể liên kết với nhau qua khóa chính 🔑 (Primary Key) và khóa ngoại 🔗 (Foreign Key).
✅ Ví dụ phổ biến:
📝 Minh họa thực tế:
Hãy tưởng tượng bạn quản lý một tiệm cà phê ☕. Bạn có một bảng “KHÁCH HÀNG”:
| 🆔 Mã KH | 🏷️ Tên | 📞 Số điện thoại | |
|---|---|---|---|
| 001 | Nguyễn A | a@gmail.com | 0987-111-222 |
| 002 | Trần B | b@yahoo.com | 0912-333-444 |
Bạn có bảng “ĐƠN HÀNG”:
| 🆔 Mã ĐH | 📅 Ngày đặt hàng | 🆔 Mã KH (🔗) | 💲 Tổng tiền |
|---|---|---|---|
| 1001 | 14/02/2025 | 001 | 150.000đ |
| 1002 | 15/02/2025 | 002 | 250.000đ |
👉 Nhờ có SQL 📜, bạn có thể dễ dàng truy vấn xem khách hàng nào đã đặt hàng, tổng tiền họ đã chi tiêu, v.v.
✨ Ưu điểm:
✅ Cấu trúc chặt chẽ, dễ tổ chức dữ liệu.
✅ Hỗ trợ truy vấn mạnh mẽ với SQL.
✅ Bảo mật cao và đảm bảo tính nhất quán.
⚠️ Nhược điểm:
❌ Cấu trúc cứng nhắc, khó thay đổi khi dữ liệu phức tạp hơn.
❌ Không phù hợp với dữ liệu phi cấu trúc.
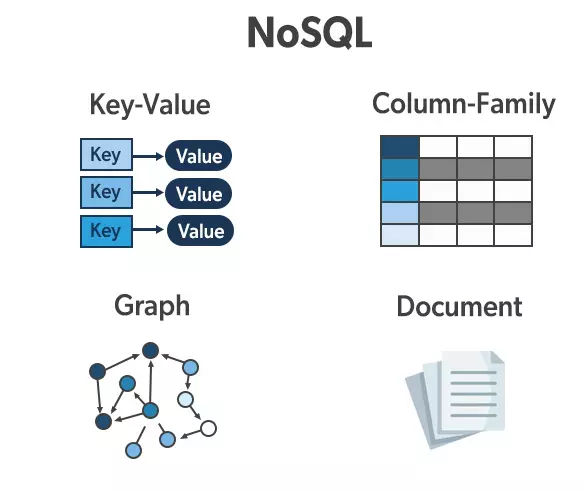
💡 Định nghĩa:
NoSQL (Not Only SQL) không sử dụng bảng cố định như RDBMS mà có thể lưu trữ dữ liệu dưới nhiều dạng khác nhau:
🔥 Các loại NoSQL phổ biến:
key:value.📝 Minh họa thực tế:
Nếu bạn đang xây dựng một ứng dụng mạng xã hội 📱, thay vì dùng bảng cố định, bạn có thể lưu thông tin người dùng bằng MongoDB như sau:
{
"user_id": "001",
"name": "Nguyễn A",
"email": "a@gmail.com",
"posts": [
{
"post_id": "101",
"content": "Hôm nay thật đẹp trời! ☀️",
"likes": 10
},
{
"post_id": "102",
"content": "Đi chơi cùng bạn bè 🏖️",
"likes": 50
}
]
}
👉 Ưu điểm: Linh hoạt, phù hợp với dữ liệu có cấu trúc không cố định như bài viết mạng xã hội, bình luận, đánh giá.
✨ Ưu điểm:
✅ Linh hoạt, không cần bảng cố định.
✅ Hiệu suất cao khi xử lý dữ liệu lớn.
✅ Tối ưu cho ứng dụng Web, Big Data, AI.
⚠️ Nhược điểm:
❌ Không hỗ trợ truy vấn SQL chặt chẽ như RDBMS.
❌ Dữ liệu có thể bị trùng lặp do không có ràng buộc.
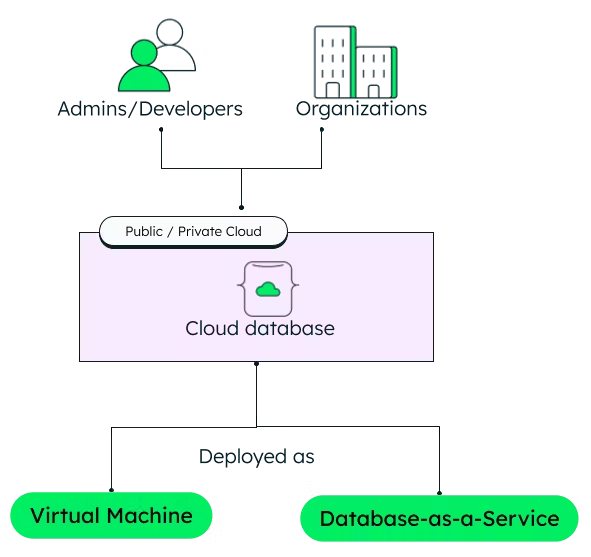
💡 Định nghĩa:
Cơ sở dữ liệu trên nền tảng đám mây giúp lưu trữ và xử lý lượng dữ liệu siêu lớn 🚀 mà không cần lo về hạ tầng máy chủ.
☁️ Ví dụ phổ biến:
SELECT customer_id, COUNT(order_id) AS total_orders
FROM orders
GROUP BY customer_id
ORDER BY total_orders DESC
LIMIT 5;
📊 Truy vấn tìm khách hàng mua hàng nhiều nhất:
📝 Minh họa thực tế:
Nếu bạn là một công ty thương mại điện tử 🛒, bạn có thể sử dụng Google BigQuery để phân tích dữ liệu khách hàng:
👉 Bạn sẽ biết TOP 5 khách hàng trung thành nhất để có thể gửi khuyến mãi 🎁 hoặc chăm sóc đặc biệt.
✨ Ưu điểm:
✅ Dễ mở rộng, phù hợp với dữ liệu rất lớn.
✅ Hỗ trợ phân tích mạnh mẽ, tích hợp với AI.
✅ Không cần quản lý máy chủ, tiết kiệm chi phí vận hành.
⚠️ Nhược điểm:
❌ Yêu cầu hiểu biết về cloud, có thể tốn phí cao nếu không tối ưu.
❌ Phụ thuộc vào kết nối Internet 🌐.
| ⚡ Loại CSDL | 📖 Định Nghĩa | 🔥 Khi Nào Nên Dùng? | 🎯 Ưu Điểm | ⚠️ Nhược Điểm |
|---|---|---|---|---|
| RDBMS 🏛️ (Cơ sở dữ liệu quan hệ) | Lưu trữ theo bảng, có ràng buộc quan hệ giữa các bảng. | Khi cần dữ liệu có cấu trúc chặt chẽ, như hệ thống quản lý doanh nghiệp, tài chính, bán hàng. | 🔹 Tính nhất quán cao 📌 🔹 Hỗ trợ truy vấn SQL mạnh mẽ 🔍 | ❌ Cứng nhắc, khó thay đổi khi mở rộng 🚧 ❌ Hiệu suất kém khi xử lý dữ liệu cực lớn 📉 |
| NoSQL 📜 (Cơ sở dữ liệu phi quan hệ) | Không dùng bảng cố định, linh hoạt với dữ liệu phi cấu trúc. | Khi làm việc với dữ liệu động, không có cấu trúc rõ ràng, như mạng xã hội, IoT, AI. | 🔹 Linh hoạt, dễ mở rộng 🚀 🔹 Tốc độ xử lý cao ⚡ 🔹 Phù hợp với dữ liệu lớn 🏗️ | ❌ Không hỗ trợ SQL mạnh như RDBMS 🤔 ❌ Có thể trùng lặp dữ liệu 🌀 |
| Cloud Database & Big Data ☁️📡 (Dữ liệu đám mây & Dữ liệu lớn) | Cơ sở dữ liệu được lưu trữ và xử lý trên nền tảng đám mây, tối ưu cho Big Data. | Khi cần phân tích dữ liệu khổng lồ, ứng dụng AI/ML, Business Intelligence. | 🔹 Khả năng mở rộng vô hạn 🌍 🔹 Xử lý dữ liệu siêu nhanh 🏎️ 🔹 Không cần quản lý hạ tầng 🛠️ | ❌ Chi phí có thể cao nếu không tối ưu 💰 ❌ Cần hiểu biết về Cloud & Big Data ☁️ |
✅ Dữ liệu có cấu trúc, cần tính toàn vẹn cao? → Dùng RDBMS 🏛️ (MySQL, PostgreSQL, SQL Server)
✅ Dữ liệu không cố định, cần mở rộng linh hoạt? → Dùng NoSQL 📜 (MongoDB, Redis, Cassandra)
✅ Dữ liệu siêu lớn, cần xử lý mạnh mẽ & AI? → Dùng Cloud Database & Big Data ☁️ (BigQuery, Snowflake, AWS Redshift)
💡 Lời khuyên:
Nếu bạn là người mới, hãy bắt đầu với MySQL hoặc PostgreSQL để nắm vững nền tảng SQL trước. Khi đã quen, bạn có thể học thêm NoSQL & Cloud Database để làm chủ dữ liệu lớn! 🚀

Chịu trách nhiệm quản lý hệ CSDL, đảm bảo bảo mật, hiệu suất và phân quyền.
📌 Quan trọng với Data Science: DBA giúp Data Scientists có quyền truy cập dữ liệu mà vẫn đảm bảo tính bảo mật.

Tham khảo : https://www.geeksforgeeks.org/dba-full-form/
Thiết kế cấu trúc dữ liệu, đảm bảo hiệu quả truy vấn và lưu trữ tối ưu.
📌 Quan trọng với Data Science: Nếu dữ liệu không được thiết kế tốt, truy vấn có thể chậm và gây lỗi trong mô hình Machine Learning.

Tham khảo : https://www.geeksforgeeks.org/database-design-ultimate-guide/
Người dùng cuối sử dụng CSDL với các mức độ khác nhau, từ cơ bản đến chuyên sâu.
📌 Quan trọng nhất cho Data Science: Sophisticated Users là nhóm Data Scientists làm việc với dữ liệu lớn và mô hình Machine Learning.
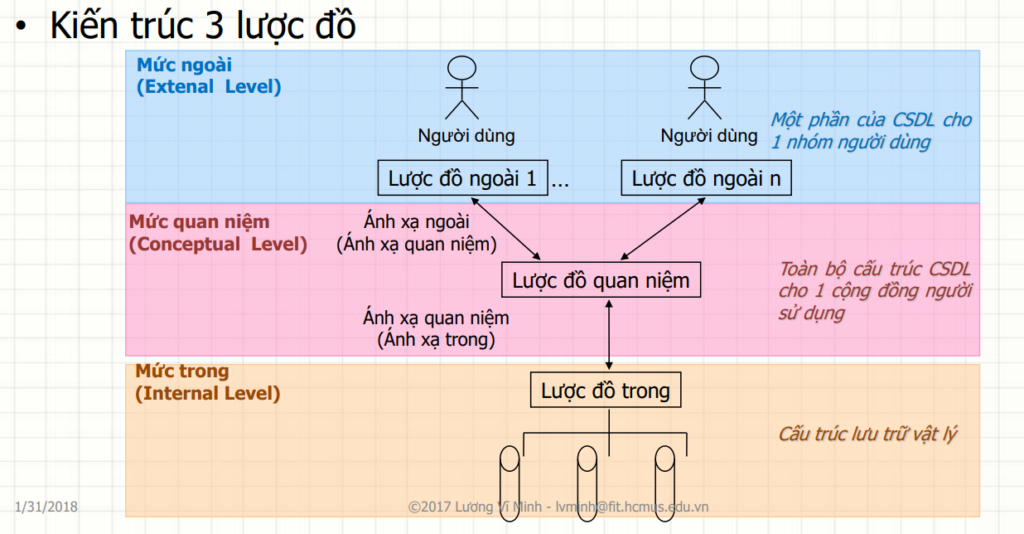
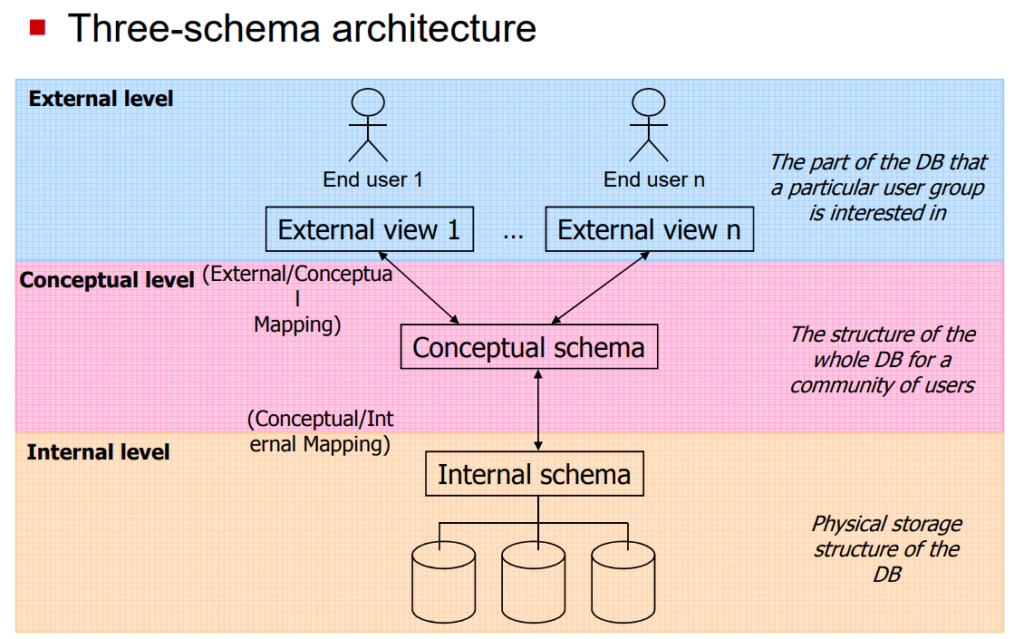
Tham Khảo : https://www.geeksforgeeks.org/introduction-of-3-tier-architecture-in-dbms-set-2/
💡 Là cách mà từng nhóm người dùng nhìn thấy dữ liệu trong CSDL. Mỗi người có thể thấy một phần dữ liệu khác nhau, tùy vào nhu cầu và quyền hạn.
🔹 Đặc điểm:
✔ Mỗi nhóm người dùng có một “góc nhìn” (View) khác nhau.
✔ Giúp bảo mật dữ liệu – người dùng chỉ thấy dữ liệu họ cần.
✔ Dữ liệu có thể định dạng khác nhau mà không ảnh hưởng đến cấu trúc CSDL thực tế.
🔎 Ví dụ thực tế:
💡 Là mô hình tổng thể của CSDL, thể hiện mối quan hệ giữa các bảng, dữ liệu và ràng buộc.
🔹 Đặc điểm:
✔ Là mô hình logic của CSDL, không quan tâm dữ liệu được lưu trữ như thế nào.
✔ Được thiết kế bởi Database Designers (DBD) để đảm bảo tính chính xác và tối ưu hóa.
✔ Chứa các bảng, khóa chính, khóa ngoại, ràng buộc toàn vẹn. ( cái này trong các buổi sql mình sẽ nói kỹ hơn nhé )
🔎 Ví dụ thực tế:
📌 Ứng dụng trong Data Science:
💡 Là cách dữ liệu được lưu trữ thực tế trên ổ cứng, bộ nhớ, hay trên cloud. ( có thể nói kỹ hơn trong 1 khóa khác hehe :> cùng đón chờ nhé cứ data là minh quất hết )
🔹 Đặc điểm:
✔ Quản lý cách dữ liệu được sắp xếp trên bộ nhớ.
✔ Sử dụng các chỉ mục (index), phân vùng (partition), nén dữ liệu (compression) để tối ưu hiệu suất.
✔ Chỉ DBA (Database Administrator) và System Engineers cần quan tâm.
🔎 Ví dụ thực tế:
📌 Ứng dụng trong Data Science:
Ví dụ minh họa 3 mức :
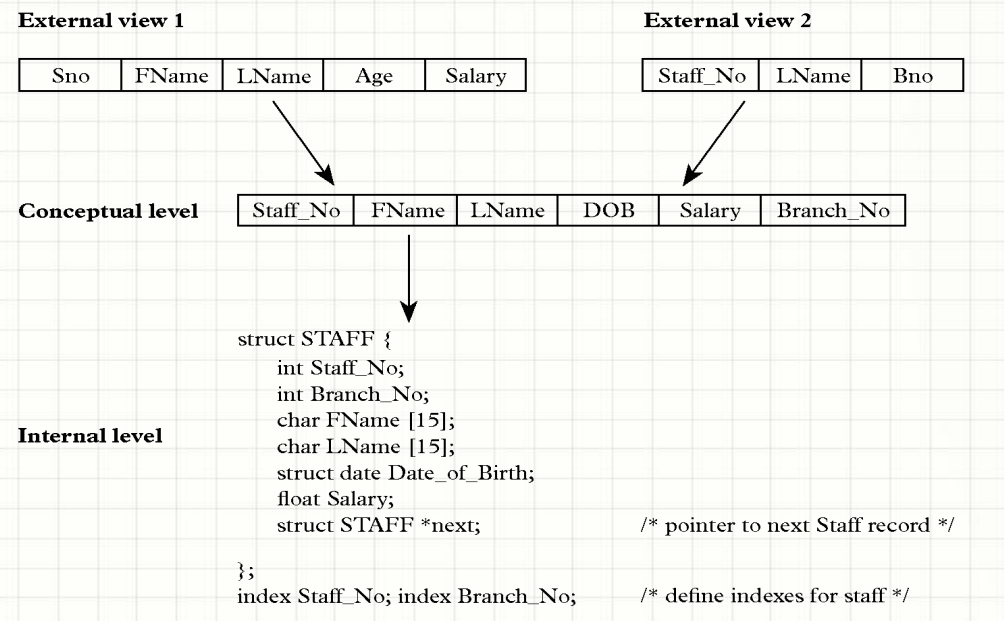
| Mức | Người sử dụng | Chức năng chính | Ứng dụng trong Data Science |
|---|---|---|---|
| Ngoài (External Level) | Người dùng cuối, nhân viên | Mỗi nhóm thấy dữ liệu khác nhau (View) | Giúp bảo mật dữ liệu, hạn chế quyền truy cập. |
| Quan niệm (Conceptual Level) | Data Engineers, Database Designers | Mô tả tổng thể dữ liệu, mối quan hệ | Giúp truy vấn dữ liệu chính xác mà không cần biết cách lưu trữ thực tế. |
| Vật lý (Internal Level) | DBA, System Engineers | Lưu trữ dữ liệu trên disk, RAM, cloud | Tối ưu hiệu suất truy vấn bằng cache, index, partitioning. |
📌 Quan trọng nhất với Data Science:
✔ Mức Quan Niệm giúp bạn hiểu được mối quan hệ giữa dữ liệu, cần thiết cho truy vấn SQL, Feature Engineering.
✔ Mức Vật Lý ảnh hưởng đến tốc độ xử lý Big Data, rất quan trọng khi làm việc với Hadoop, Spark, Google BigQuery.
🚀 Giờ bạn đã hiểu cách CSDL hoạt động từ ngoài vào trong! 🎉
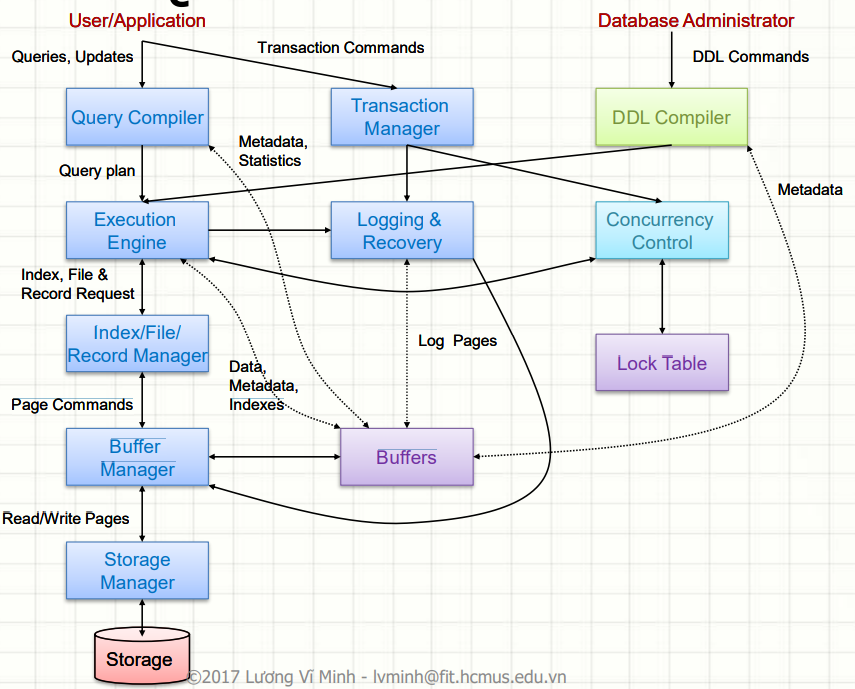
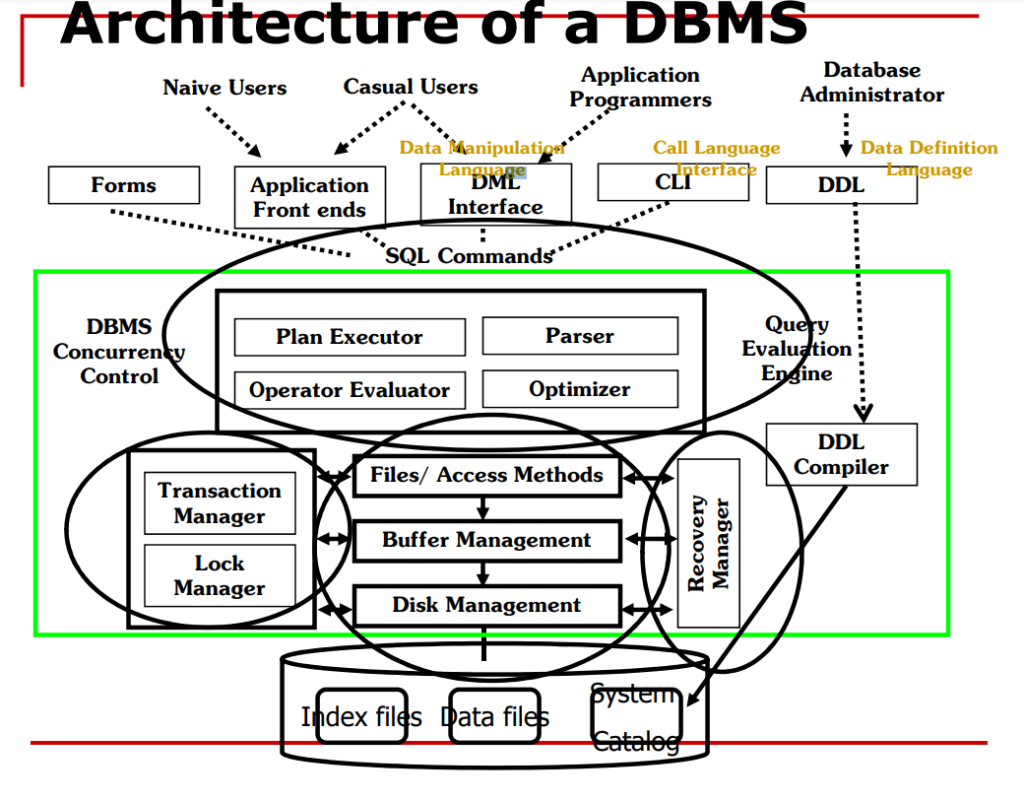
Giải Thích Khái Niệm Trong Hình :
Biên dịch các lệnh DDL (VD: CREATE TABLE, ALTER TABLE, DROP TABLE) để định nghĩa và thay đổi cấu trúc dữ liệu.
Biên dịch và tối ưu hóa truy vấn (VD: SELECT, JOIN) nhằm đảm bảo hiệu năng khi xử lý dữ liệu lớn.
Quản lý giao dịch đảm bảo các tính chất ACID (VD: thực hiện rollback khi có lỗi) giúp duy trì tính nhất quán của dữ liệu.
Thực thi các query đã được tối ưu, đảm bảo trả về kết quả chính xác (VD: xử lý truy vấn phức tạp với nhiều điều kiện).
Ghi nhận log và khôi phục dữ liệu khi gặp sự cố (VD: phục hồi dữ liệu sau lỗi phần cứng).
Quản lý truy cập đồng thời của nhiều người dùng (VD: sử dụng lock table khi cập nhật dữ liệu) để đảm bảo tính nhất quán.
Quản lý dữ liệu, chỉ mục và cách lưu trữ trên file, giúp tăng tốc độ truy vấn (VD: tạo chỉ mục cho cột thường dùng tìm kiếm).
Điều khiển việc lưu trữ dữ liệu vật lý (VD: quản lý phân vùng trên đĩa cứng hoặc lưu trữ đám mây).
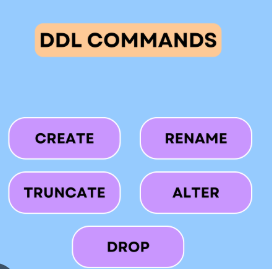
Tham Khảo : https://shareprogramming.net/sql-ddl-dml-tcl-and-dcl/
Books để lưu thông tin về sách. Bạn có thể sử dụng lệnh DDL như sau: CREATE TABLE Books (
BookID INT PRIMARY KEY,
Title VARCHAR(255),
Author VARCHAR(255),
PublishedYear INT,
Genre VARCHAR(100)
);CREATE TABLE thuộc DDL và được dùng để tạo bảng Books.BookID (khóa chính), Title, Author, PublishedYear, và Genre.Books vào danh mục của nó.Books trong cơ sở dữ liệu, sẵn sàng để lưu trữ dữ liệu về sách.Books. Bạn có thể sử dụng SDL để chỉ định rằng:
BookID nên được lưu trữ dưới dạng chỉ mục (index) để tăng tốc độ tìm kiếm.Books nên được lưu trữ trên ổ SSD thay vì HDD để cải thiện hiệu suất. Ví dụ cụ thể trong SQL Server: CREATE CLUSTERED INDEX idx_BookID ON Books (BookID);CLUSTERED INDEX) trên cột BookID, giúp sắp xếp dữ liệu vật lý theo thứ tự của BookID.BookID.Books sẽ được lưu trữ hiệu quả hơn, và các truy vấn tìm kiếm dựa trên BookID sẽ nhanh hơn.
CREATE VIEW RecentBooks AS
SELECT Title, Author, PublishedYear
FROM Books
WHERE PublishedYear > 2000;CREATE VIEW tạo một view mới tên là RecentBooks.Title, Author, và PublishedYear của những sách được xuất bản sau năm 2000.RecentBooks để xem danh sách các sách gần đây mà không cần viết lại câu lệnh SQL phức tạp.
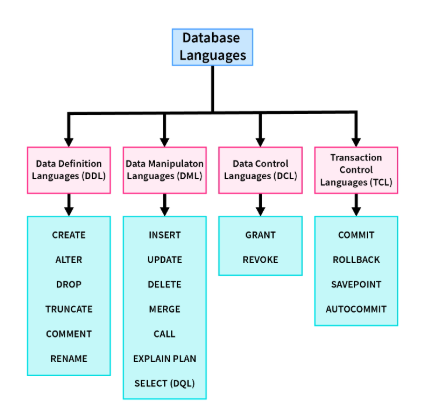
SELECT * FROM Books WHERE Genre = 'Science';Books bằng cách sử dụng PL/SQL (ngôn ngữ thủ tục của Oracle). Bạn có thể viết đoạn mã như sau:BEGIN INSERT INTO Books (BookID, Title, Author, PublishedYear, Genre) VALUES (101, 'The Universe', 'Stephen Hawking', 1988, 'Science'); END;INSERT để thêm một quyển sách mới vào bảng Books.Nó được nhúng trong một khối PL/SQL, nơi bạn phải chỉ định rõ ràng các bước thực hiện.Books.| Loại ngôn ngữ | Mục đích | Ví dụ thực tế |
|---|---|---|
| DDL | Định nghĩa cấu trúc dữ liệu (bảng, cột, ràng buộc, v.v.). | Tạo bảng Books để lưu thông tin sách. |
| SDL | Định nghĩa cách lưu trữ dữ liệu vật lý. | Tạo chỉ mục trên cột BookID để tăng tốc độ tìm kiếm. |
| VDL | Định nghĩa các view để người dùng truy cập dữ liệu dễ dàng hơn. | Tạo view RecentBooks để hiển thị sách xuất bản sau năm 2000. |
| DML | Thao tác với dữ liệu (truy xuất, chèn, xóa, sửa đổi). | Sử dụng SELECT để tìm sách có thể loại “Khoa học”. |
Như vậy, các ngôn ngữ trong cơ sở dữ liệu giúp định nghĩa, lưu trữ và thao tác với dữ liệu một cách hiệu quả và phù hợp với nhu cầu của người dùng lẫn hệ thống.
✅ Hiểu CSDL là gì & vai trò trong Data Science.
✅ Nắm lịch sử phát triển từ hệ thống tập tin đến Cloud Database.
✅ Biết các loại Database: SQL, NoSQL, Big Data.
✅ Biết cách thao tác SQL với DDL & DML.
✅ Học cách kết nối với MySql database in vscode.
🔥 Kết Thúc – Nhưng Cũng Là Một Khởi Đầu Mới! 🔥
Vậy là chúng ta đã cùng nhau đi qua những kiến thức quan trọng trong bài đầu tiên của series “Database for Data Science”! 🚀 Nhưng đây chỉ là điểm khởi đầu cho một hành trình dài hơn, nơi chúng ta sẽ tiếp tục khám phá, học hỏi và làm chủ CSDL để áp dụng vào Data Science và Machine Learning! 💡💾
Mình biết rằng việc học một lĩnh vực mới đôi khi có thể gây hoang mang, nhưng đừng lo! Hãy cứ từ từ tiếp thu, thử nghiệm, và quan trọng nhất là đừng ngại đặt câu hỏi! 🤔💬 Nếu bạn có bất kỳ thắc mắc hay góp ý nào, hãy để lại bình luận hoặc nhắn tin cho mình nhé! 📩
🔥 Sắp tới, chúng ta sẽ cùng Loser1 khám phá những kiến thức cực kỳ quan trọng! 🔥
🚀 Bạn đã sẵn sàng chưa? Chặng đường phía trước sẽ còn hấp dẫn hơn nữa, khi chúng ta bước vào thế giới của Mô Hình Dữ Liệu và những phương pháp thiết kế CSDL đỉnh cao! 🧠💡
📌 Những chủ đề cực kỳ thú vị đang chờ đợi chúng ta:
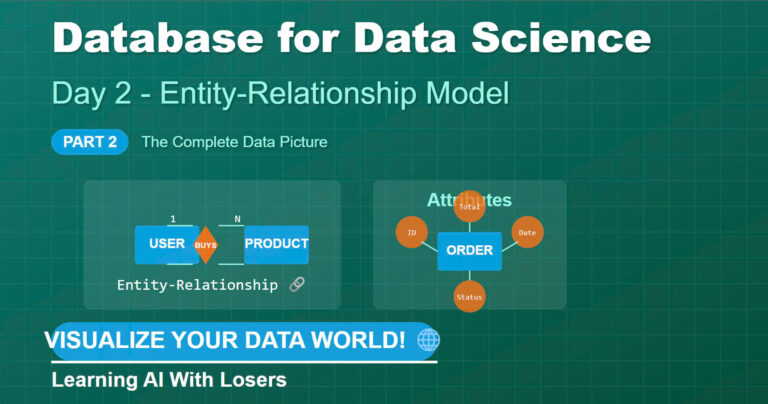
🔹 MÔ HÌNH DỮ LIỆU (DATA MODEL) – Cách dữ liệu được tổ chức và quản lý! 🔄💾
🔹 MÔ HÌNH THỰC THỂ – KẾT HỢP (ENTITY-RELATIONSHIP) – Cách biến dữ liệu thực tế thành mô hình trực quan! 📊🖥️
🔹 Quá trình thiết kế CSDL 🎨🛠️
✅ Mô hình E/R – Hiểu rõ các thực thể và mối quan hệ! 🔗
✅ Thiết kế – Bước chuyển từ ý tưởng thành hệ thống thực tế! 🏗️
✅ Ví dụ minh họa – Áp dụng thực tế để hiểu sâu hơn! 🎯
✨ Tiếp tục với BÀI 2: CẤU TRÚC DỮ LIỆU VÀ MÔ HÌNH CSDL! ✨
💠 Mô hình quan hệ (Relational Model) – Cách hoạt động của CSDL quan hệ! 🔄🔢
💠 Mô hình NoSQL – Khi nào nên dùng Key-Value, Document, Graph, Column? 📂⚡
💠 OLTP vs OLAP – Khi nào dùng cái nào? Hệ thống giao dịch hay phân tích dữ liệu? 🔥🔍
💪 Sẵn sàng bước vào chặng tiếp theo chưa? Chắc chắn bạn sẽ không muốn bỏ lỡ đâu! Hãy cùng nhau tiếp tục chinh phục Database for Data Science! 🚀🔥